First a little background. I’m working on a large fact table that behaves itself as a slowly changing type 2 dimension. Weird right? But I have a good reason for this: it’s a snapshot table and if I would create the snapshots like you’re supposed to (by exploding the fact table) I would end up with over 320 million rows with a couple of million rows added each month. Let’s say it was a bit too much for the server in question. Let’s quickly illustrate with some data to show what I’m talking about.
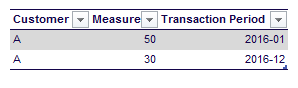
Suppose I have a customer with the following two transactions:
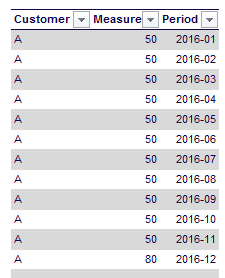
We’re going to keep track of the cumulative total of the measure using a snapshot table (similar like a stock keeping table or the balance of an account). If we would explode the transaction table, we end up with 12 rows:
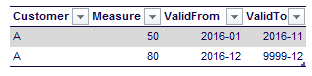
However, by designing the table like a type 2 changing dimension – thus with two dates indicating the validity range – we only have two rows (the same number as in the transaction table):
Therefore, by designing the fact table as a slowly changing dimension type 2 I could solve the initial size problem and the final table would only hold 16 million rows instead of 320 million. In order to speed up performance, I created a clustered columnstore index on the fact table (SQL Server 2014). The scenario was a bit more difficult than the example here, because some dimensions where actually type 2 changing dimensions, which means that the surrogate key can change during an interval. This means we have to insert extra rows (with the same value for the measures) into the snapshot table, just to make sure we can keep track of the history of the dimension members.
Now on to the topic of the blog post.
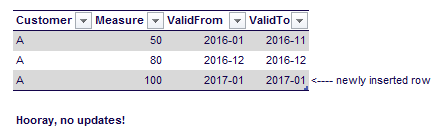
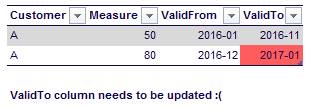
I created a script that did the initial load of the fact table by loading one month at the time. Then I loaded the next month, comparing it with the previous month. If anything had changed (a surrogate key value or a measure), I inserted a new row into the table. After the insert, I had to update the ValidTo column of the previous period to make sure the interval was set correctly. Initially, when I inserted new rows, the ValidTo column was set to the current period. In that case, if there was a change in the next period I didn’t have to update the ValidTo column. For example:
However, if there was no update for customer A, I have to update the ValidTo column to the current period.
Turns out the majority of the rows belonged to the second scenario. Whoops. The initial run took a little over 20 hours. Not exactly rocket speed. The problem was that for each period, a large number of rows in the clustered columnstore index (CCI) had to be updated, just to set the range of the interval. Updates in a CCI are expensive, as they are split into inserts and deletes. Doing so many updates resulted in a heavily fragmented CCI and with possibly too many rows in the delta storage (which is row storage).
A small adjustment however lead to much better results. Instead of setting the ValidTo column to the current period, let’s set it to a period in the future. In this case 9999-12. Now the ValidTo column needs to be updated only for records that actually had changed, which were in the minority. The run time of the initial load script now became 6 hours. Quite a difference.
(Why didn’t I do this in the first place? My period table only goes up to the current period – which helps with LastNonEmpty measures in the cube – so it seemed a logical choice at first)
Conclusion
Try to avoid updates on a clustered columnstore index at all costs. Think well about your loading strategy and how you can optimize your updates. It might be even beneficial to delete rows first and then insert them again with the new values. Read more in the blog post Clustered Columnstore Indexes – part 28 (“Update vs Delete + Insert”) by Niko Neugebauer (blog | twitter).
Today I was having a nice discussion with some colleagues about Fabric and pricing/licensing came…
I recently purchased and read the book Deciphering Data Architectures - Choosing Between a Modern…
A while ago I had a little blog post series about cool stuff in Snowflake. I’m…
I have the pleasure to announce I'll be presenting at two conferences this spring. The…
You might know the feeling: you're writing code in a Notebook in Microsoft Fabric and…
I was trying some stuff out in a notebook on top of a Microsoft Fabric…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
View Comments
I think that a clustered column store index update does a delete and insert so it why would it be of any benefit for application code to do this?
Hi Tom,
in my case I altered the logic so there would be much less updates, but a bit more inserts.
However, inserts are a lot faster than updates.
Regarding the remark that it's sometimes better to do delete + insert instead of plain update, check out the blog post by Niko:
http://www.nikoport.com/2014/03/17/clustered-columnstore-indexes-part-28-update-vs-delete-insert/
Basically with the update statement, it seems all rows went directly into the delta store, while with a separate insert statement they can directly go into the row group. Big difference.