I’m starting a little series on some of the nice features/capabilities in Snowflake (the cloud data warehouse). In each part, I’ll highlight something that I think it’s interesting enough to share. It might be some SQL function that I’d really like to be in SQL Server, it might be something else.
In the first part: the GENERATOR function. In short, it lets you generate a virtual table with a specified number of rows, or in database lingo: a tally table (or numbers table). A tally table can help you solve a lot of problems in SQL, but the TL;DR version is that it replaces loops/cursors most of the time and allows you to tackle the issue in a true set-based manner.
In SQL Server, you have some options to generate a tally table:
- use some tool like SSIS to generate a persisted table, once. This takes up storage and you’d have to create a table big enough to satisfy all your tally table needs.
- do a cross join between two large system tables. For example, 10,000 rows cross-joined with another 10,000 rows gives you 100 million rows. That’s a lot of possible iterations. You can find an example here.
- use common table expressions and – again – cross joins to generate your list. You can find examples here and here.
Personally I use the last option most of the time. The only problem is I can never remember the syntax 🙂
In Snowflake, we don’t have to dabble with complex SQL to get our tally table, we have the GENERATOR function. It’s basically a table function where you can specify the following things:
- the number of rows
- the number of seconds you want the function to be running
- or both
An example:
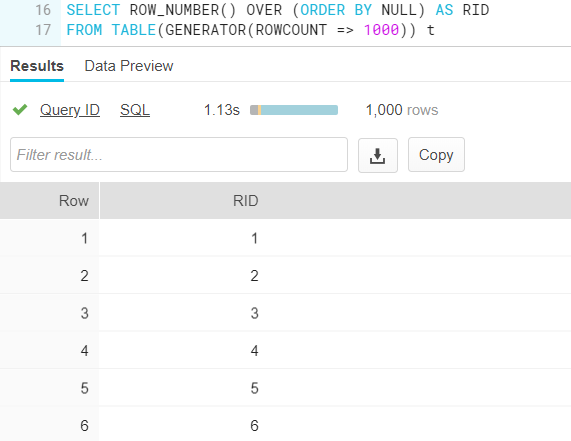
Generating dates:
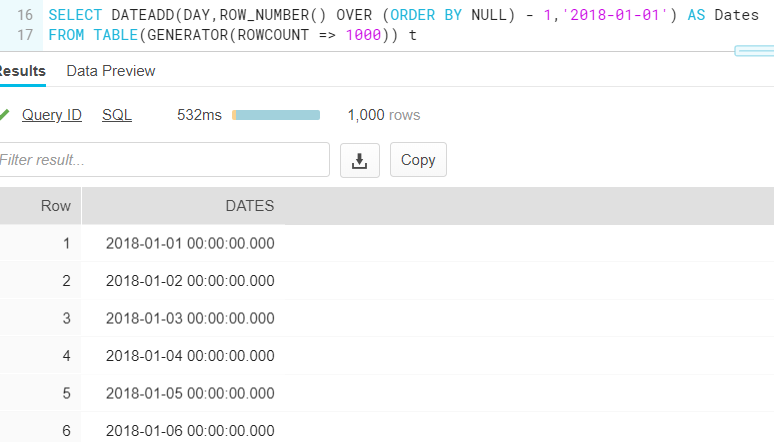
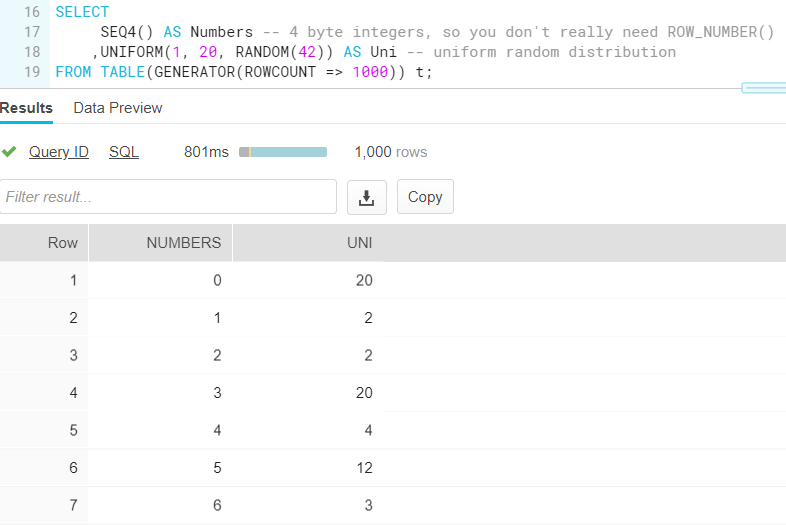
You can also use other functions to generate different types of number distributions:
Wondering how many rows Snowflake can generate in 10 seconds? (with an X-Small warehouse)
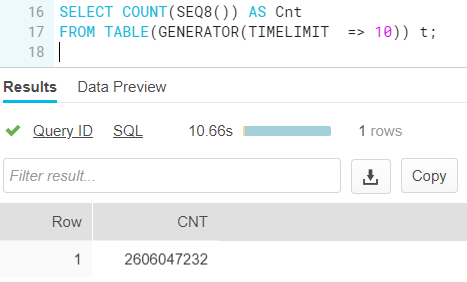
Around 2.6 billion. I tried to generate the same amount of rows on my machine with SQL Server, but I cancelled the query after 5 minutes. In SQL Server, it’s relatively easy to generate millions of rows. For billions, you need a faster machine 🙂
If you want something similar in SQL Server, you can upvote this feedback item, which has been open since forever (from the good ol’ Connect days).
------------------------------------------------
Do you like this blog post? You can thank me by buying me a beer 🙂
For those that came here looking how to fix the gaps in the data (or random numbers that should not be there), drop SEQ4() and use ROW_NUM() OVER (order by 1) instead.
You are welcome
If you try the following in SQL Server you’ll find it is just as quick as Snowflake at generating numbers, 2 billion in about 9 seconds, 3 billion in around 13 seconds. Just like in SQL Server if you choose the wrong way to write your query in Snowflake then you’ll have time to think about what you did wrong while you wait for the query to finish.
;with N(O) as (
SELECT ROW_NUMBER() OVER(ORDER BY (SELECT null)) FROM
(VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) t1 (n)
,(VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) t2 (n)
,(VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) t3 (n)
,(VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) t4 (n)
,(VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) t5 (n)
,(VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) t6 (n)
,(VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) t7 (n)
,(VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) t8 (n)
,(VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) t9 (n)
,(VALUES (0),(0)) t10 (n)
)
select COUNT_BIG(1) from N
Hi Malcolm,
I used pretty much the same query as the one you posted in your comment (the Itzik Ben-Gan style cross join). It’s been a while since I wrote this blog post, so I don’t remember if I counted the rows (like in Snowflake and in your query) or actually had them as output (which would have been severely slowed down by the capabilities of SSMS). I ran a little test in Snowflake where I had it return the rows instead of counting them, and it was capable of generating 146,288,640 rows, of which 11,939,840 were shown in the browser. On my machine, it takes about one minute to show 10 million rows in SSMS (again, you can probably blame SSMS more than the database engine).
Anyway, the point of the blog post was not performance, but rather the easy to use syntax to generate a tally table.