I’m doing a little series on some of the nice features/capabilities in Snowflake (the cloud data warehouse). In each part, I’ll highlight something that I think it’s interesting enough to share. It might be some SQL function that I’d really like to be in SQL Server, it might be something else.
Let’s start with SPLIT. Splitting string is something most of us have to do from time to time. In SQL Server, we had to wait until SQL Server 2016 when the table-valued function STRING_SPLIT came along. The syntax of both functions is exactly the same. You specify the string to split and the delimiter.
Before 2016, we had to help ourselves with home-brew solutions, such as cursors (the horror), CLR (don’t get me started) or functions using tally tables (good performance, but harder to write). One of those functions is the excellent CSV splitter function by Jeff Moden. In SQL Server, using the new built-in function looks like this:
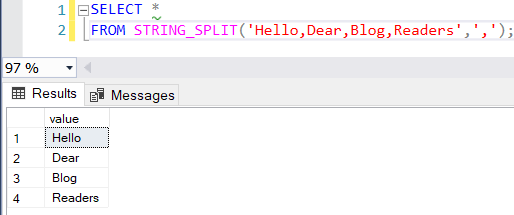
In Snowflake, we do this:
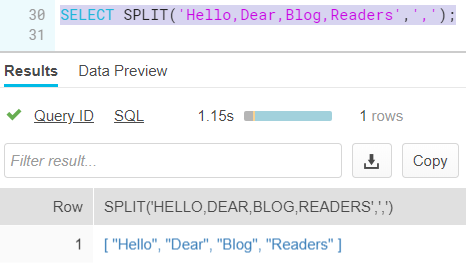
Oops, quite a difference. Unlike SQL Server, the SPLIT function is a regular function, not a table-valued function. Which means that instead of a result set, an array is returned (whoah, aren’t arrays used in those fancy programming languages such as R and Python?).

To deal with this array, the function FLATTEN comes into the picture. Basically, the FLATTEN function explodes a compound value (such as an array) into a multiple rows. The syntax now becomes (granted, a bit harder to write):
SELECT s.*
FROM
(
SELECT 'Hello,Dear,Blog,Readers' AS TestString
) tst
, LATERAL FLATTEN (INPUT => SPLIT(tst.TestString,',')) s;
The output now becomes:
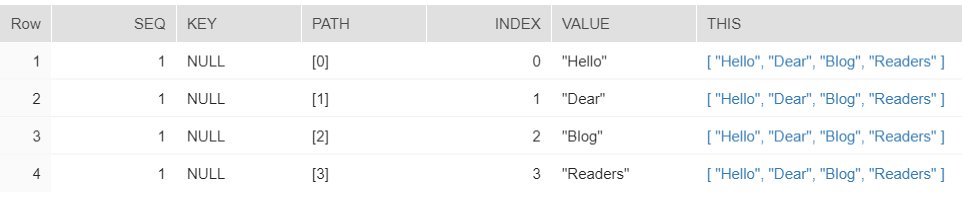
Again. Whoah. Something totally different. Now we have:
- a sequence number. Which is always 1 because we passed only a single input value. If you would parse 100 rows, you would get the sequences 1 till 100.
- a key. Only relevant for maps and objects.
- the path. Which is a pointer to the location of the element within the original structure.
- the index. Only applicable for arrays and the same as the path (only the data types are different).
- the value of the element. Unfortunately surrounded by quotes, but that’s nothing a REPLACE or SUBSTRING can’t fix.
- the original structure. Word of caution: it is included for every row. If you flattened a 10MB string with 50,000 elements, you now get 50,000 times 10MB in the output. Oopsies. Only include if necessary.
So you get a ton of extra information. Most of the time you are interested in the index and the value. In SQL Server, you only get the value with the STRING_SPLIT function. Jeff Moden’s function also returns an index.
If you only need a specific part of the original string, you can rather use SPLIT_PART instead:
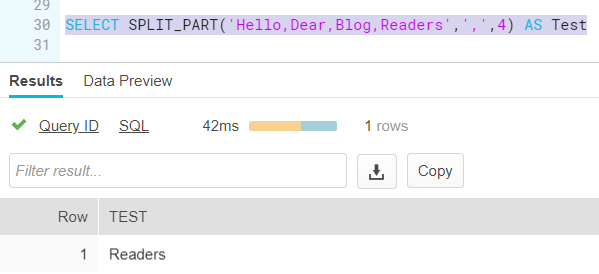
In this blog post, we only touched the surface of what we can do with semi-structured data sources and FLATTEN. You can for example use it to easily parse XML as well, without having to learn that pesky XPATH. More on that in a future blog post!
Other parts in this series:
------------------------------------------------
Do you like this blog post? You can thank me by buying me a beer 🙂
Very Scala esque…….
Have a look at the split_to_table function which does the flatten automatically:
select table1.value from table(split_to_table(‘a.b’, ‘.’)) as table1 order by table1.value;