I’m doing a little series on some of the nice features/capabilities in Snowflake (the cloud data warehouse). In each part, I’ll highlight something that I think it’s interesting enough to share. It might be some SQL function that I’d really like to be in SQL Server, it might be something else.
This blog post is one of the more awesome features in Snowflake: Time Travel.

Time travel in Snowflake is similar to temporal tables in SQL Server: it allows you to query the history rows of a table. If you delete or update some rows, you can retrieve the status of the table at the point in time before you executed that statement. The biggest difference is that time travel is applied by default on all tables in Snowflake, while in SQL Server you have to enable it for each table specifically. Another difference is Snowflake only keeps history for 1 day, configurable up to 90 days. In SQL Server, history is kept forever unless you specify a retention policy.
How does time travel work? Snowflake is built for the cloud and its storage is designed for working with immutable blobs. You can imagine that for every statement you execute on a table, a copy of the file is made. This means you have multiple copies of your table, for different points in time. Retrieving time travel data is then quite easy: the system has only to search for the specific file that was valid for that point in time. Let’s take a look at how it works.
First I create a sample table and insert some sample data:
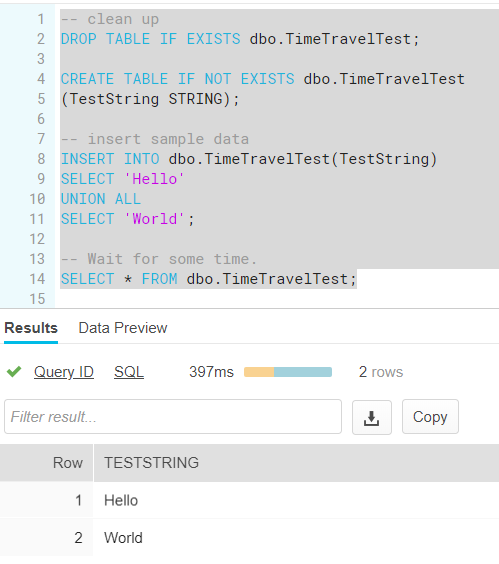
Next, we insert some other data as well:
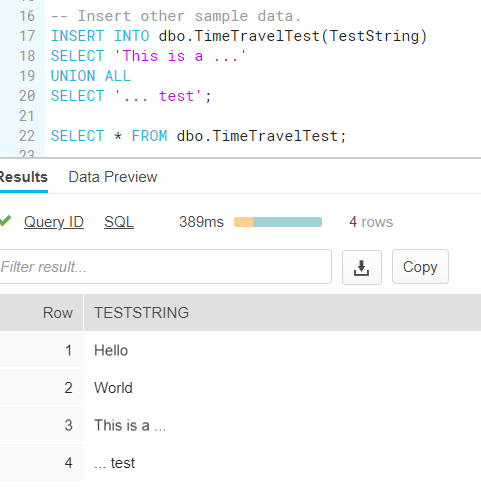
We can now retrieve the status of the table before we executed this last statement. There are three options:
- you specify a specific point-in-time
- you specify an offset, for example 5 minutes ago
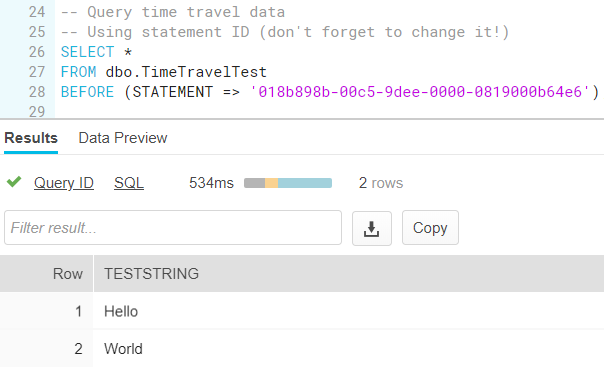
- you specify a query ID. Time travel will return the data before the specified query was executed.
Let’s try the last option (you can read more about finding the query ID in the blog post Cool Stuff in Snowflake – Part 6: Query History):
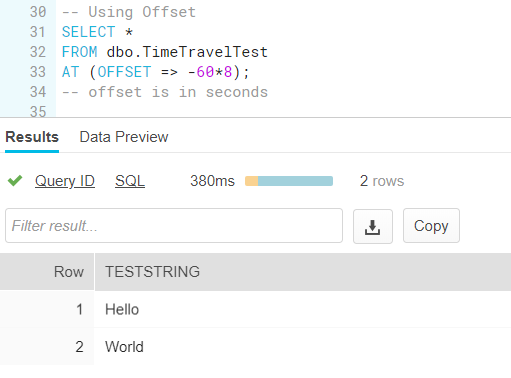
We can also use an offset, which is measured in seconds. In the example below we go 8 minutes back in time:
Does it also work with TRUNCATE TABLE? Why yes, it does:
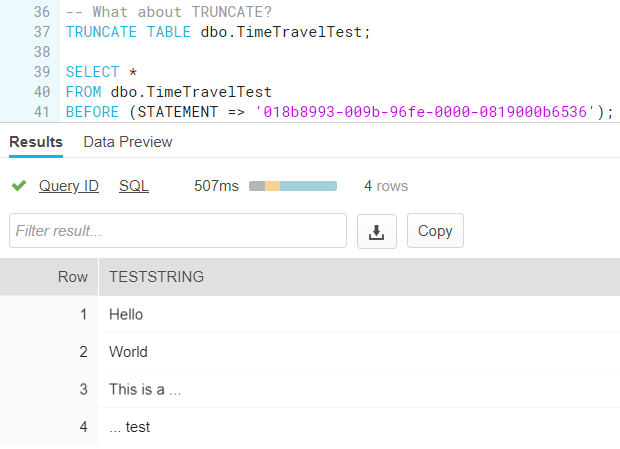
And what about dropping the table? Let’s first insert some sample data again (because we truncated the table, remember?) and then try it out.
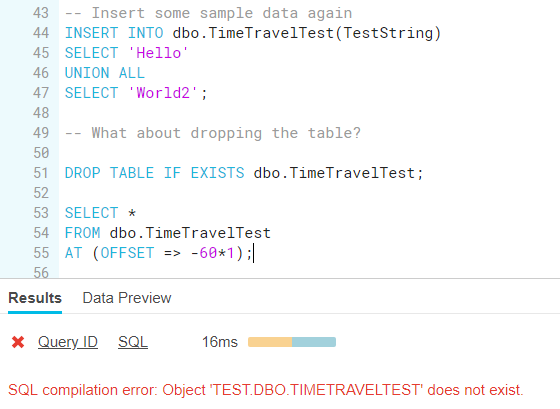
That doesn’t sound too good. Luckily we can use another time travel feature: UNDROP TABLE. This statement is important, not only because it’s your best friend when you accidentally dropped a table (or other objects like a schema or a database), but also because Snowflake doesn’t have back-ups like you know them in SQL Server. If something goes wrong, you have to correct it using time travel features. You can find info about all tables and if they are dropped with the statement SHOW TABLES HISTORY:
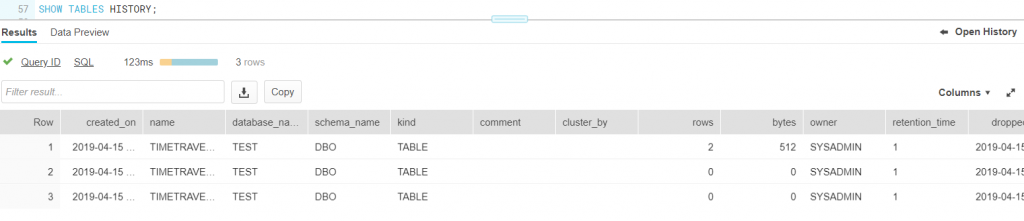
Now we can restore the table:
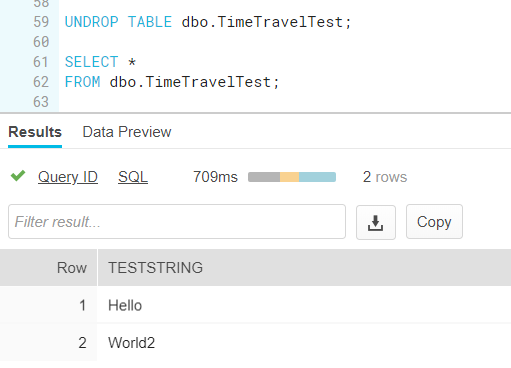
Once the table is restored, time travel works again:
Pretty nifty, right? You can read more about time travel in the documentation.
------------------------------------------------
Do you like this blog post? You can thank me by buying me a beer 🙂
The one thing it won’t do that would be really nice would be to give you something like a type-2 slowly changing dimension for the last 24 hours.
Hey Andrew, can’t you just self join the table to an 24 hours earlier version of it and write out all changed rows to an SCD2 table?