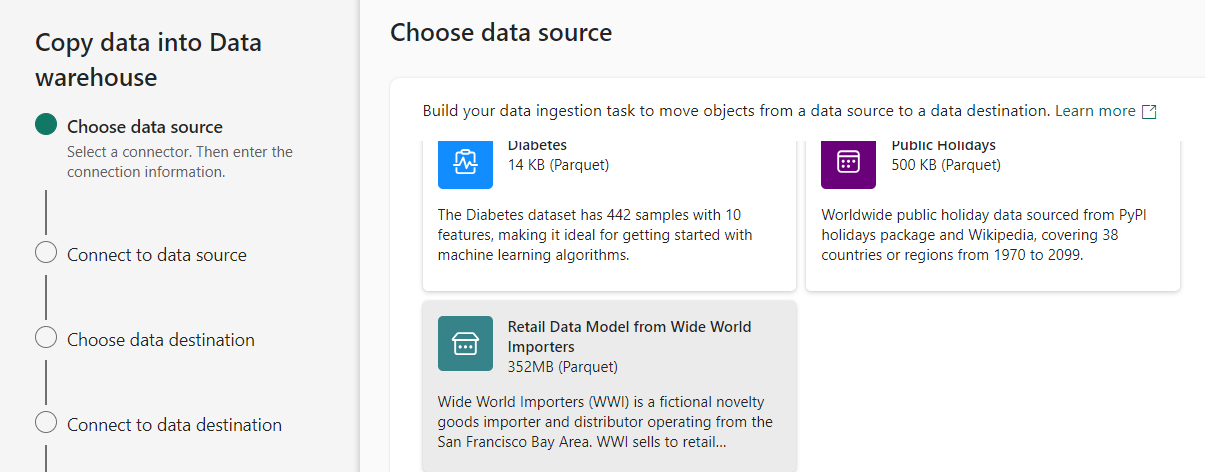
I loaded some built-in sample data from Wide World Importers into a Fabric warehouse. You get an option to load sample data when you create a new pipeline in Fabric.
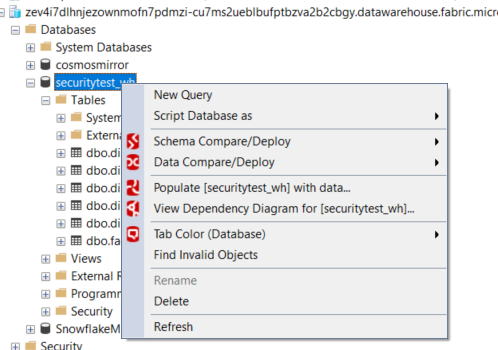
It says the data is 352MB in size, but after loading the data I was curious about how many rows were actually in that sample data set. Unfortunately, it’s not as straight forward as with a “normal” SQL Server database to get the row counts. First of all, when you connect with SSMS to the database there’s sadly no option to get the row counts report:
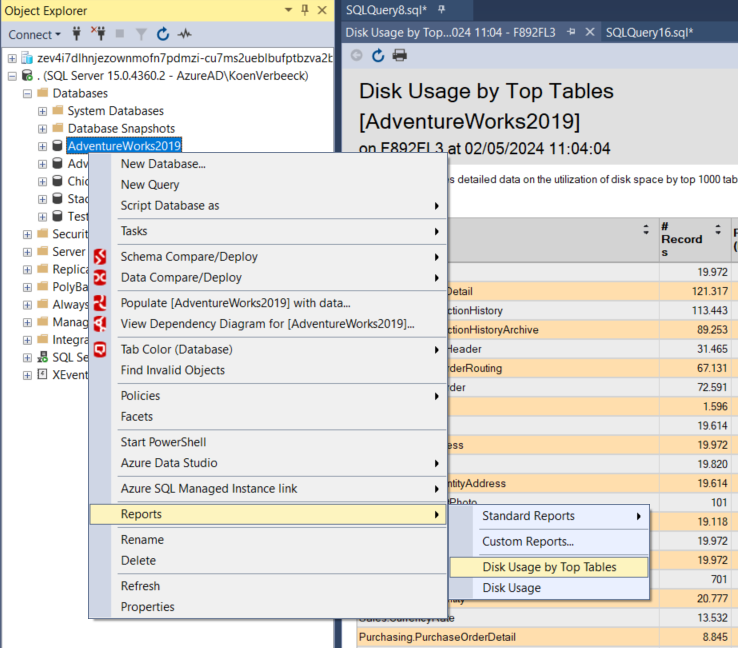
For contrast, this is with a regular SQL Server database (Azure SQL DB doesn’t have this report either though):
So let’s turn to some SQL querying. I googled a bit and got this article as one of the first hits: SQL Server Row Count for all Tables in a Database. Let’s go over the different options.
sys.partitions
This system views returns an approximate row count.
SELECT
TableName = QUOTENAME(SCHEMA_NAME(sOBJ.schema_id)) + '.' + QUOTENAME(sOBJ.name)
,[RowCount] = SUM(sPTN.[Rows])
FROM sys.objects sOBJ
JOIN sys.partitions sPTN ON sOBJ.object_id = sPTN.object_id
WHERE sOBJ.[type] = 'U'
AND sOBJ.is_ms_shipped = 0x0
AND index_id < 2 -- 0:Heap, 1:Clustered
GROUP BY sOBJ.schema_id
,sOBJ.name
ORDER BY TableName;
The result:
Not really that useful.
sys.dm_db_partition_stats
SELECT
TableName = QUOTENAME(SCHEMA_NAME(sOBJ.schema_id)) + '.' + QUOTENAME(sOBJ.[name])
,[RowCount] = SUM(sdmvPTNS.row_count)
FROM sys.objects sOBJ
JOIN sys.dm_db_partition_stats sdmvPTNS ON sOBJ.object_id = sdmvPTNS.object_id
WHERE sOBJ.type = 'U'
AND sOBJ.is_ms_shipped = 0x0
AND sdmvPTNS.index_id < 2
GROUP BY sOBJ.schema_id, sOBJ.[name]
ORDER BY [TableName];
But alas…
If you’re wondering, the DMVs sys.dm_db_index_physical_stats and sys.dm_db_stats_properties are also not supported.
statistics
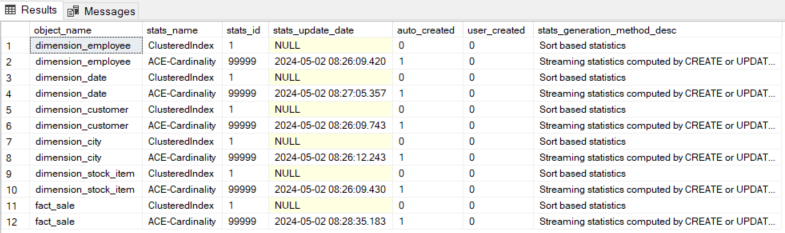
The following query returns the statistics objects on our (user) tables:
SELECT
object_name = OBJECT_NAME(s.object_id)
,stats_name = s.[name]
,s.stats_id
,stats_update_date = STATS_DATE(s.object_id, s.stats_id)
,s.auto_created
,s.user_created
,s.stats_generation_method_desc
,s.*
FROM sys.stats s
JOIN sys.objects o ON o.object_id = s.object_id
WHERE o.[type] = 'U';
Unfortunately, DBCC SHOW_STATISTICS isn’t that helpful:
The ACE-Cardinality holds a row count according to the docs, but it’s not queryable:
We can however create a manual statistic with a full scan:
CREATE STATISTICS DimEmployee_EmployeeKey ON dbo.dimension_employee(EmployeeKey) WITH FULLSCAN;
And get the information using DBCC STATISTICS:
DBCC SHOW_STATISTICS('dimension_employee','DimEmployee_EmployeeKey') WITH STAT_HEADER
However, creating a statistics object on each table on a column that has a unique value for each row (this might be hard to find for a fact table) and then querying it with DBCC seems a bit cumbersome. Also, I would like the results in a format I can store in a table.
So let’s try the brute-force method where we just count the rows.
SELECT COUNT(1)
The stored proc sp_MSforeachtable is not available in Fabric (it seems we have no luck today):
So let’s use some plain old dynamic SQL. From that same MSSQLTips.com article:
DECLARE @QueryString NVARCHAR(MAX);
SELECT @QueryString = COALESCE(@QueryString + ' UNION ALL ','')
+ 'SELECT '
+ '''' + QUOTENAME(SCHEMA_NAME(sOBJ.schema_id))
+ '.' + QUOTENAME(sOBJ.[name]) + '''' + ' AS [TableName]
, COUNT(*) AS [RowCount] FROM '
+ QUOTENAME(SCHEMA_NAME(sOBJ.schema_id))
+ '.' + QUOTENAME(sOBJ.[name])
FROM sys.objects AS sOBJ
WHERE sOBJ.[type] = 'U'
AND sOBJ.is_ms_shipped = 0x0
ORDER BY SCHEMA_NAME(sOBJ.schema_id), sOBJ.[name];
EXEC sp_executesql @QueryString;
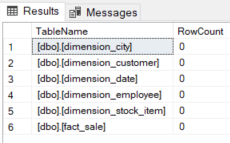
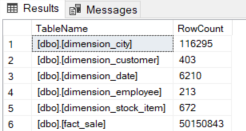
The results:
At the moment, it seems the only method to get reliable row counts for all tables is to do a SELECT COUNT(1) on each table. You can use statistics, but that method seems more work than it is worth. The upside of using SELECT COUNT(1) is that you might trigger automatic data compaction for the table.
With some dynamic SQL, you can create a reusable script that you can run on each warehouse (or SQL Analytics endpoint). You can modify it to store the results in a table.
I'm starting a webinar series about SQL Server indexing with the fine folks of MSSQLTips.com.…
A while ago I blogged about a use case where a pipeline fails during debugging…
Quite the title, so let me set the stage first. You have an Azure Data…
At Saturday the 21st of February I'm presenting an introduction to dimensional modelling at dataMinds…
I'm not trying to start up a debate whether you should use tabs or spaces…
The Power BI Enhanced Report Format (PBIR) will soon become the default, and that's a…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
View Comments
Alas.. it can be done!
/* ==================================================================================================================
Author: Daniel S. Davis
Create date: 2024-12-08
Description: Used to process all user tables in a provided database and return an output of tables with record counts
Parameters:
Database: name of database to execute against
Max_Recursion: OPTIONAL if set will force break loop after recursion number is reached
==================================================================================================================== */
CREATE PROCEDURE [json].[fetch_table_counts]
@database SYSNAME
,@max_recursion INT = NULL
AS
BEGIN
SET NOCOUNT ON;
-- DECLARE VARIABLES
DECLARE @sql NVARCHAR(MAX),
@json NVARCHAR(MAX),
@remaining_tables INT = 0,
@current_table VARCHAR(100),
@record_count BIGINT,
@EXEC NVARCHAR(MAX) = QUOTENAME( @database ) + N'.sys.sp_executesql';
-- FETCH TABLES FROM sys.tables
-- Parse into JSON so data can be accessed and extended without distributed processing
SET @sql = N'
SELECT @json = output
FROM (
SELECT
tbl.name AS table_name
, tbl.create_date AS table_created
, tbl.modify_date AS table_updated
, CONVERT(BIGINT,NULL) AS records
FROM
sys.tables tbl
INNER JOIN sys.schemas sch
ON sch.schema_id = tbl.schema_id
WHERE
sch.name = ''dbo''
AND tbl.type = ''U''
FOR JSON AUTO
) JSON (output)';
EXEC @EXEC
@sql,
N'@json NVARCHAR(MAX) OUTPUT',
@json = @json OUTPUT;
-- Initially all tables have null records since distributed processing doesn't capture row counts
SELECT @remaining_tables = COALESCE(COUNT(*),0) FROM OPENJSON(@json) WITH (
table_name VARCHAR(75) '$.table_name',
table_created DATETIME2(6) '$.table_created',
table_updated DATETIME2(6) '$.table_updated',
records BIGINT '$.records'
)
WHERE records IS NULL;
-- Iterate until there are no remaining_tables
WHILE @remaining_tables > 0
BEGIN
-- Fetch next table that doesn't have records yet
SELECT @current_table = MIN(table_name) FROM OPENJSON(@json) WITH (
table_name VARCHAR(75) '$.table_name',
table_created DATETIME2(6) '$.table_created',
table_updated DATETIME2(6) '$.table_updated',
records BIGINT '$.records'
)
WHERE records IS NULL;
-- Dynamic SQL to fetch record count from target database
SET @sql = N'SELECT @record_count = COALESCE(COUNT(1),0) FROM ' + QUOTENAME(@current_table);
EXEC @EXEC
@sql,
N'@record_count BIGINT OUTPUT',
@record_count = @record_count OUTPUT;
-- Extend and reassign @json
SELECT @json = output
FROM (
SELECT
js.table_name
, js.table_created
, js.table_updated
, COALESCE(manual.records,js.records) as records
FROM OPENJSON(@json) WITH (
table_name VARCHAR(75) '$.table_name',
table_created DATETIME2(6) '$.table_created',
table_updated DATETIME2(6) '$.table_updated',
records BIGINT '$.records'
) js
LEFT JOIN (
-- STATIC table with results from record query
SELECT @current_table, @record_count
) manual (table_name, records)
ON LOWER(manual.table_name) = LOWER(js.table_name)
FOR JSON AUTO
) JSON (output);
-- UPDATE processing count based on updates
SELECT @remaining_tables = COALESCE(COUNT(*),0) FROM OPENJSON(@json) WITH (
table_name VARCHAR(75) '$.table_name',
table_created DATETIME2(6) '$.table_created',
table_updated DATETIME2(6) '$.table_updated',
records BIGINT '$.records'
)
WHERE records IS NULL;
IF @max_recursion IS NOT NULL
BEGIN
SET @max_recursion = @max_recursion - 1;
IF @max_recursion <= 0
BEGIN
PRINT 'FORCE BREAK'
SET @remaining_tables = 0;
END
END
END
SELECT * FROM OPENJSON(@json) WITH (
table_name VARCHAR(75) '$.table_name',
table_created DATETIME2(6) '$.table_created',
table_updated DATETIME2(6) '$.table_updated',
records BIGINT '$.records'
)
END
go
Not being able to get the number of records for all the tables (or a subset) is indeed an important issue in certain scenarios.
In SQL Server 2000 I used cursors for retrieving the same, and the solution seems to work also in Microsoft Fabric warehouses, respectively SQL databases.
See post: https://sql-troubles.blogspot.com/2025/01/sql-reloaded-number-of-records-v-via.html