In the introduction of this blog post series, I explained the use case: extracting data from the Planview Portfolios REST API using Azure Data Factory. Any tool that can send HTTPS requests can work with the REST API, but our focus here is ADF (which can also be Synapse Pipelines or Fabric Pipelines).
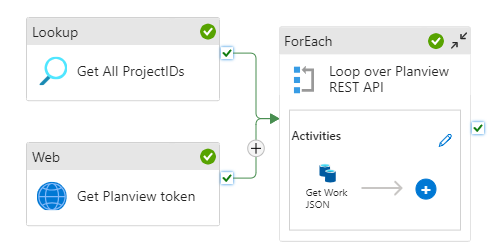
In the previous parts, I fetched the list of project IDs from an OData feed in the Lookup Activity and I fetched the access token with a Web Activity. In this last part, we’re going to look over the project IDs and for each ID, we’re going to fetch the related work from a REST API endpoint using the Copy activity.
In the ForEach loop settings, the items are configured with the following expression:
@activity('Get All ProjectIDs').output.value
To access the Planview Portfolios REST API in the Copy activity, we need to add a REST API linked service:
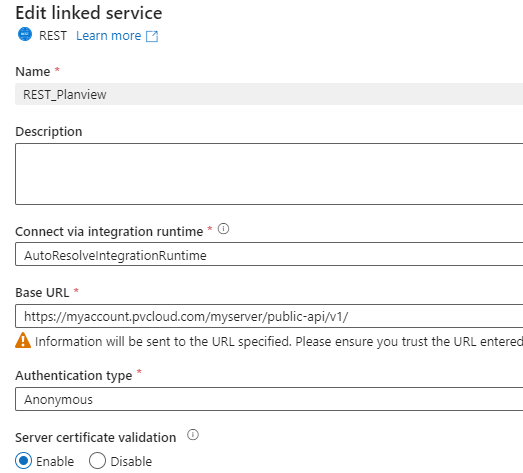
This linked service only stores the base URL to the Planview Portfolios public REST API for your account. We also need to create a REST dataset:
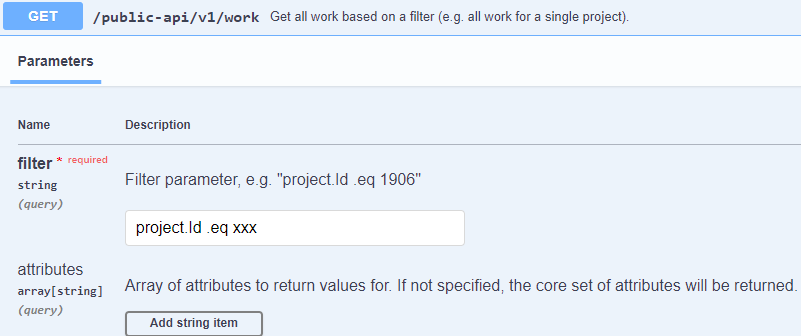
We’re using the work endpoint, which has the following configuration:
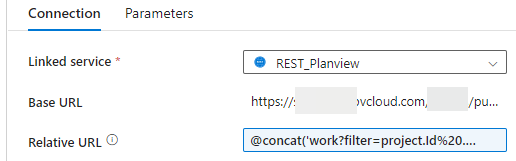
This means we need to pass the project ID to this endpoint. We’re adding it as a parameter of the dataset:
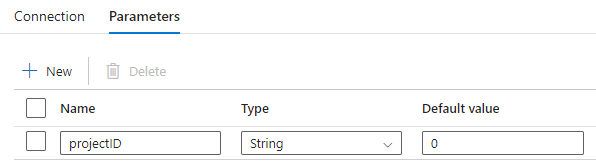
And then we use this parameter in an expression for the relative URL:
@concat('work?filter=project.Id%20.eq%20',dataset().projectID)
Don’t forget to replace the spaces with %20. Once we have the linked service and the dataset, we can configure the source of the Copy activity:
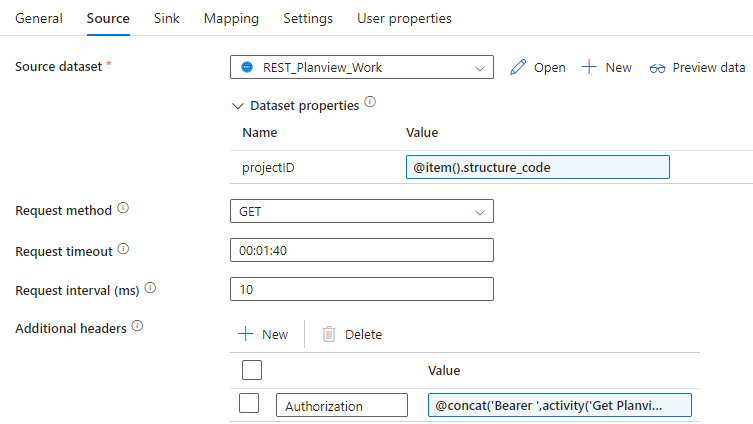
We pass the current project ID to the dataset parameter using the expression @item().structure_code. We also add an Authorization header with the following expression:
@concat('Bearer ',activity('Get Planview token').output.access_token)
For the sink, I’m using a table in an Azure SQL DB that has just one VARCHAR(MAX) column, that will store the entire JSON output for a single project into a row. If we have 400 projects, we will have 400 rows with each row a single JSON file. The REST API endpoint returns a lot of attributes (331 to be exact), so it’s a bit too complicated to try to parse this directly in the Copy activity. You could also dump this in a data lake as JSON files, I opted for a SQL table so I could parse the data with OPENJSON. You should be able to pass along which attributes you want to the endpoint, so you get a less complicated JSON, but that is out of scope for this blog post. The sink configuration looks like this:
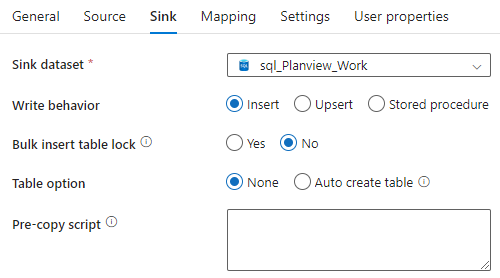
Don’t truncate the table in the pre-copy script, as this would empty your table before each project is loaded and you end up with data only for the last project. You typically want your TRUNCATE TABLE before the ForEach loop in a Script activity. The sink dataset points to the desired table which is hosted in whatever SQL database you like (well, not the Fabric warehouse because that one doesn’t support VARCHAR(MAX) at the time of writing).
The mapping looks like this:
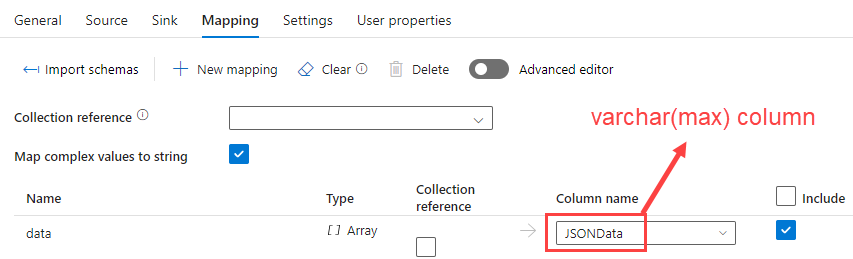
JSONData is our VARCHAR(max) column. Data is an array in the JSON response containing the actual work data for a specific project. A sample response looks like this:
{
"data": [
{
"structureCode": "string",
"scheduleStart": "2024-05-26T12:07:37.204Z",
"scheduleFinish": "2024-05-26T12:07:37.204Z",
"scheduleDuration": 0,
"actualStart": "2024-05-26T12:07:37.204Z",
"actualFinish": "2024-05-26T12:07:37.204Z",
"calendar": {
"structureCode": "STANDARD",
"description": "Standard Calendar"
},
"status": {
"structureCode": "WBS20$OPEN",
"description": "Open / Active"
},
"isMilestone": true,
"project": {
"structureCode": "24601",
"description": "Test Project ABC"
},
"place": 2,
"parent": {
"structureCode": "90125",
"description": "Test Entity DEF"
},
"description": "string",
"hasChildren": true,
"depth": 5,
"constraintDate": null,
"constraintType": "ASAP",
"progressAsPlanned": true,
"enterStatus": false,
"ticketable": true,
"hasTimeReported": true,
"doNotProgress": true,
"attributes": {
"POINTS_EARNED": 20,
"Wbs24": {
"structureCode": "164"
}
}
}
]
}
When we now run the entire pipeline, the Lookup activity fetches the list of projects from the OData feed, the Web activity fetches the access token, and the ForEach loop iterates over all those projects. Each iteration of the loop calls the Work endpoint of the REST API and stores the JSON result in the database.
It’s possible you need to do some slight adjustments to the JSON to make it actually valid if there are multiple items in the data array.
The only “problem” we now have with this setup is that we are doing a REST API call for each project. If you have 500 projects (which is not that unreasonable for larger organizations), that’s 500 API calls, but also 500 times we’re executing the Copy activity. In ADF pricing, that is not good, since you are billed at least one minute each time the Copy activity starts. That’s 500 minutes of execution time (even though the actual execution time of the pipeline might be only 10 minutes). The cost formula for the data movement activities is:
#number of DIU * #copy duration in hours* $0.25
With the lowest amount of DIU configured (this is two, but you have to explicitly set it in the Copy activity settings), we get:
2 * (500 / 60) * $0.25 = $4.17
This means it costs $4.17 to run this pipeline once. You can get costs down by limiting the number of projects we want to extract data from (maybe only those who are running, if dates are provided), or we can move the actual REST API to another form of compute that is cheaper, for example Logic Apps or Azure Functions. If you use Azure Functions in a serverless Function App, the first million executions are free.
The real problem is of course that Planview Portfolios public REST APIs doesn’t have a bulk API. If you think the REST API doesn’t suit your needs, you can try checking out if writing queries and exporting the results is a better match.
The other parts of this series:
------------------------------------------------
Do you like this blog post? You can thank me by buying me a beer 🙂