In this blog post, I’ll draw a quick comparison between both ETL tools. It is certainly not my intention to say that one tool is better than the other. I’m just stating observations I’ve done from working with both tools (although PDI for a much shorter time). I’m writing this blog post just to inform people and it might be of some assistance when selecting an ETL tool.
User Interface
Both tools are graphical ETL designers. Both have boxes and arrows, sort of speak. SSIS is designed in Visual Studio (SQL Server Data Tools), which can be viewed as an advantage and a disadvantage at the same time. PDI is a tool on its own, written in Java. Again, that can be seen as an advantage and a disadvantage. Because it’s Java, it can run on any platform (PDI seems to be very popular with the Linux crowd). But then again, it’s Java (owned by Oracle, you know what I’m saying). SSIS on the other hand can only be developed on a Windows machine, but it can run on Windows and on Linux (since the latest versions).
SSIS has some clunky UI features which haven’t been updated since 2005: the notepad editors for SQL statements, the one-line editor for the derived column. PDI looks quite nice and most components are easily configured. A very cool feature is that you can drop a transformation on an arrow between two existing transformations and the new transformation is inserted right between the two. Marvelous. In SSIS, you have to delete the precedence constraint, add the task and create two new precedence constraints.
Example. One arrow:
Boom, two arrows:
Magic.
Orchestration
Both tools have a similar structure: SSIS has a control flow for executing tasks and a data flow for transforming data in-memory, all in the same package. PDI has jobs for handling tasks and transformations for handling data (both are separate objects). However, in my opinion, the control flow in SSIS makes it a bit easier for orchestrating complex flows: you have precedence constraints which you can assign OR and AND logic to; you have containers for grouping logical units together. In PDI, I find it much harder to organize dependencies. Most of the time, I have to make another job just to make sure something doesn’t run in parallel when it doesn’t need to.
Side note, just because you can create complex flows in SSIS, doesn’t mean you have to. Please don’t do this.
Available Transformations
SSIS has lots of transformations. PDI has even more. Lots of basic transformations you would probably do in SSIS with a derived column, are available in PDI as out-of-the-box components. Some examples:
You also have a “calculator” and a “formula” transformation that help you creating expressions. Most transformations in PDI are also a bit more powerful than their SSIS counterparts:
- most of them support regular expressions. SSIS has never heard of them. Want them? Write a custom component, use a 3rd party component or use a script task/component.
- some source transformations (like reading an Excel workbook or flat file) support reading more than one file at once. You just specify a folder, the metadata and you’re good to go, PDI will read all the files and append them to the output. In SSIS, you have to set-up a for each loop container, configure expressions, use variables. Much more work.
- most output support parallelism out of the box. Want to write to three files at once? No problemo. In SSIS you have to use a conditional split to split up your stream or use the balanced data distributor. Then configure all your outputs.
Let’s elaborate on that last item. In PDI, you right-click your destination and change the number of copies to start. Let’s take 3.
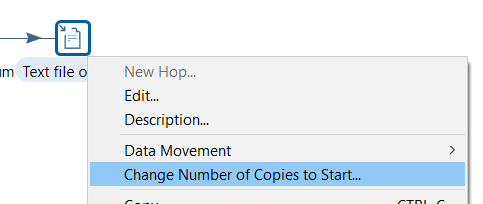
The destination will now write to three different files in a round-robin fashion (other options are available as well). In the file output, you can also easily add the step number (which of the three outputs was used) and a timestamp to the file name. In SSIS, this requires lots of configuration (ugh, those expressions to add a timestamp to a file…).
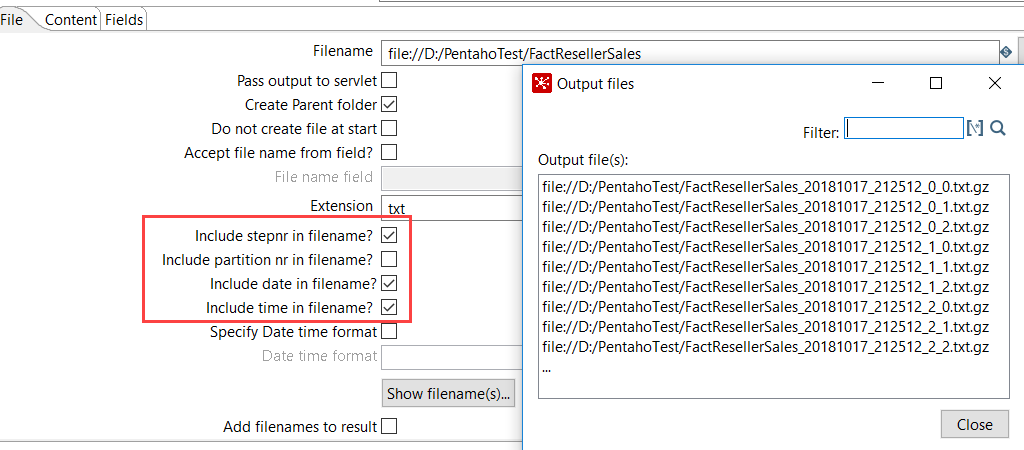
Oh yeah, you can also zip the files right out-of-the-box. In short, in most cases, PDI has more ease of development.
Connectivity
SSIS can connect to a lot of source. PDI as well. SSIS has more connectors for Azure (obviously), PDI has connectors for other sources, like AWS S3 (although it’s quite buggy). Both support ODBC connections. SSIS prefers OLE DB, PDI prefers JDBC. You have probably for most sources both providers available, or at least an ODBC provider. SSIS has project connection managers, PDI has shared connections and the support of JNDI files (connections are defined in a separate file and shared throughout your project).
Extensibility
In SSIS, you can extend pretty much anything with .NET. You can write your own task/components or use script tasks/components. In PDI, you have a JavaScript transformation and a User Defined Java Class transformation (which is very similar to a script component). PDI also has a marketplace for plugins (supported by the community), where you can download even more transformations or connectors.
SSIS really shines in debugging the .NET script tasks/components. Your basically developing in Visual Studio, so you have access to breakpoints, debugger, intellisense and so on. In PDI? Not so much. The Java Class is basically writing code in notepad (no, not notepad++). You have a bit of coloring and that’s it. Debugging? Not as good. You can run the transformation with sample rows and see what the output is.
Source Control
SSIS can integrate with TFS (on-premises or the cloud version) and git (because it’s Visual Studio remember). PDI can integrate with git as well (you can set up repositories which are then managed by git). Personally, I find the source control integration with SSIS a bit better and more straight forward because it’s all in one tool (Visual Studio).
Performance
I haven’t done extensive testing yet. SSIS is very fast (if configured properly), but can’t handle any changing metadata at all. PDI is also in-memory and you have the same pitfalls as in SSIS (blocking transformations like sorting data, lookups that need caching etc). PDI can more easily configured to run certain transformations in parallel, as I described above. Also, because you can write and zip a file at the same time, you can skip some steps while with SSIS you have to sequentially perform them.
Automation
For generating SSIS packages, you need to rely on Biml (much about that can be found on this blog or on the net), or older frameworks such as ezApi. Or you need 3rd party tools such as BimlStudio or TimeXtender. Using Biml means writing XML and .NET. Don’t get me wrong, I love Biml and I use it a lot in my SSIS projects.
But generating transformations in PDI is so much easier. First, you create a template (you create a transformation, but you leave certain fields empty, such as the source SQL statement and the destination table). Then you have another transformation reading metadata. This metadata is pushed to the template using the Metadata Injection Transformation. In this transformation, you point to the template and you map those empty fields to your metadata fields.
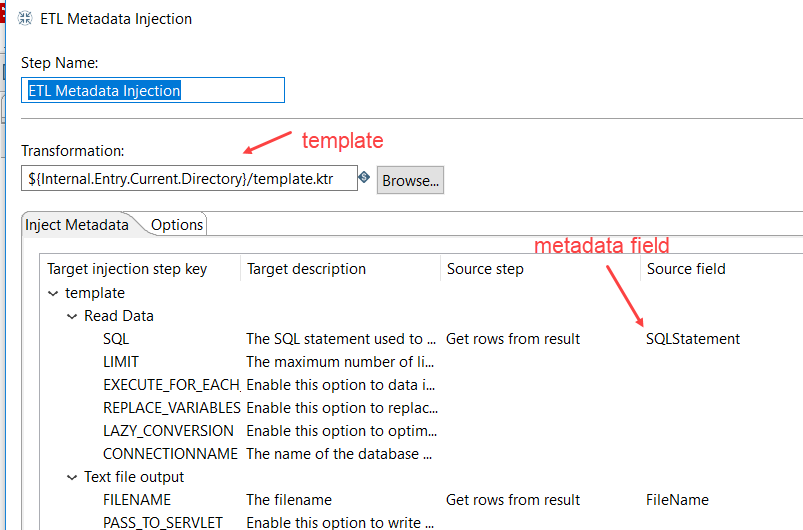
When you run the transformation, it fills in the blanks of the template, effectively creating a new transformation. You can either run this transformation immediately, or save it to a folder. It’s the same concept as Biml, but WITHOUT WRITING A SINGLE LINE OF CODE. MAGIC.
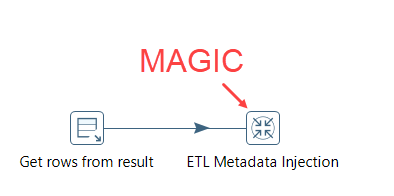
How I wish SSIS has something similar. It would return Biml completely obsolete (sorry Varigence). The only upside of Biml is that it can generate control flows and data flows (you know, entire SSIS packages). With the metadata injection transformation, you can only generate other transformations, not jobs. Boo.
Conclusion
Which one to choose? As usual, it depends. Want a cross-platform tool? PDI definitely. Love the .NET? SSIS. Already have a SQL Server license? SSIS for sure, no brainer. The advantage of SSIS is its tight integration with the rest of the SQL Server stack. You can process SSAS cubes, you can schedule packages with SQL Server Agent, environment configuration is done in the SSIS catalog.
PDI has in my opinion a better developer experience and certainly a better automation story. Orchestration is a bit easier in SSIS. Maybe the question is how relevant both tools still are in the changing data landscape: everything is moving to the cloud where EL(T) make more sense.
------------------------------------------------
Do you like this blog post? You can thank me by buying me a beer 🙂
Good stuff!
I recently got acquainted with Pentaho (I inherited an ETL solution), and the most obvious thing with regards to performance was that I couldn’t figure out how to make it bulk insert (“fast load”) data into SQL Server. In the end, Pentaho was inserting data row-by-row, which took a considerable toll on performance. SSIS was an order of magnitude faster in this regard.
Tip: if any reader out there is stuck with this problem, try delayed durability (SQL Server 2014 and newer, iirc), which batches commits instead of waiting for log writes for each individual row. This gave me a 30-40% performance increase on RBAR inserts.
Hi Daniel,
we don’t use SQL Server at my current project, so I haven’t tested the fast load performance. However, I’ve noticed when using other products that Pentaho does indeed send data over row-by-row. If you configure the “batch settings”, it sometimes keeps sending RBAR, but rather commits the entire batch at once instead of committing each row.
Thanks Koen Verbeeck for the comparison
Thanks Koen Verbeeck!