Recenty I was writing an article for MSSQLTips where I had to create a treemap (it will be published soon). As sample data, I used the different folders containing the drafts for all the tips I ever wrote. As measures, I have the number of kilobytes and the number of items per folder. An example:
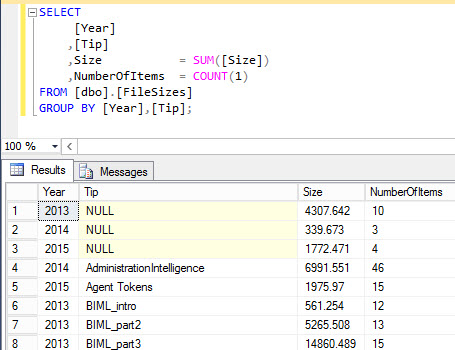
As you can see, the measures are easy to calculate using the GROUP BY clause and the standard aggregate functions SUM and COUNT. Nothing special here.
Now I want to calculate the highest number of items I can find in a folder, but without resorting to subqueries or CTEs. I want to keep the query clean. Window functions can easily do the trick of course. Using an empty OVER clause, you can find the highest number of the total set. This type of syntax can also be used to find the grand total or example. The syntax should be valid from SQL Server 2005.
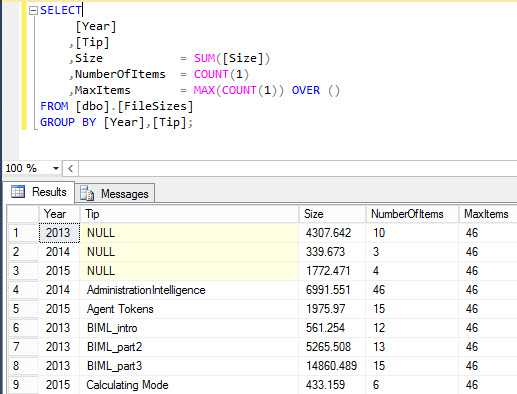
And now we have something special: nested aggregates. We have the COUNT aggregate, which belongs to the GROUP BY and we have the MAX aggregate which is a window function. The reason why we can reference the result of the COUNT function inside the window functions is because window functions are calculated after the GROUP BY. The query is in a way equivalent to this:
SELECT [Year] ,[Tip] ,Size = SUM([Size]) ,NumberOfItems = COUNT(1) ,MaxItems = MAX(NumberOfItems) OVER () FROM [dbo].[FileSizes] GROUP BY [Year],[Tip];
This syntax is not valid of course, since you cannot reference an alias in the same SELECT statement, but you get the point. It’s possible to nest aggregates into each other, but it can lead to confusing TSQL, such as SUM(SUM(myColumn) OVER (). On the other hand it leads to concise code. If you nest aggregates, maybe add some comments to the code to clarify for the person coming after you.
For more information, read the book Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions by Itzik Ben-Gan. It’s a great book, not too long and it explains in great detail how window functions work. It also explains the order in which a query is evaluated by SQL Server.
------------------------------------------------
Do you like this blog post? You can thank me by buying me a beer 🙂