This book was recommended by some of my colleagues, so I decided to give it a try. After finishing the book, I was pleased that I did. As the title might give away, it’s a book about data engineering, but not from a pure technical perspective. It won’t teach you how to write Python or how to work with Kafka. It rather talks about what makes a good data engineer; it talks about what the building blocks are for a solid, robust data platform; it talks about all the other things that go beyond technology, such as governance, devops, data management, security and so on. In my opinion, the book is a great companion for the Deciphering Data Architectures book by James Serra.
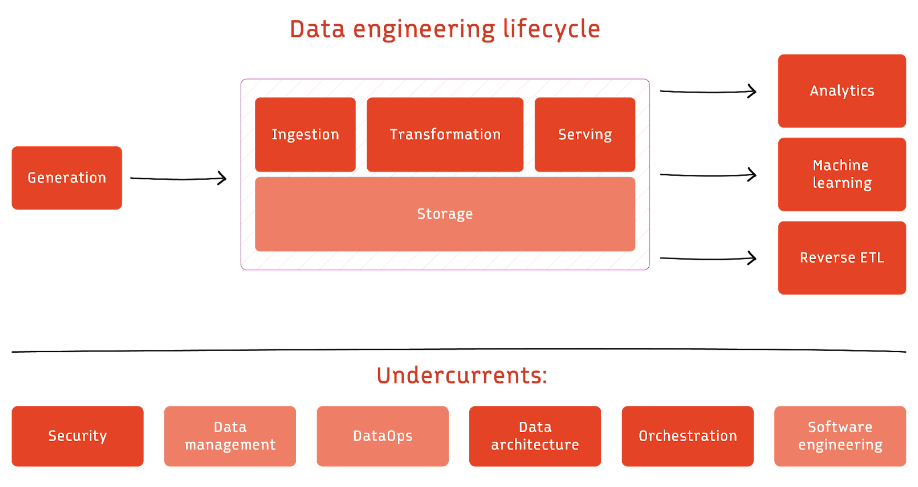
The authors introduce their view on the data lifecycle and the concepts of the “undercurrents”, practices that support every part of the lifecycle. From the RedPanda website, the following visualization depicts the proposed data lifecycle:
The book goes into great length to give you enough foundation for every part of the data lifecycle, but it doesn’t lose itself in details. Each chapter talks about a certain part of the lifecycle and explains what common pitfalls are, what you should pay attention to, what the typical stakeholders are et cetera.
One very interesting part was the authors’ forecast that data platform will move towards streaming-only in the future. I’m curious how that will turn out to be.
I definitely recommend the book to every one who wants to take their data engineering skills to the next level, not on a technical plane, but more on an architectural one. I’m not 100% sure I’d recommend this book to someone just starting out in the field, as it might be a bit overwhelming. I think it wouldn’t hurt if you already have some experience contributing to the development of a data platform, as it will help you putting some stuff from the book in context.
If you’re interested in this book, you can of course purchase a copy at your favorite book retailer, but you can also get a free copy (in exchange for your contact information of course) at the RedPanda website.
Disclaimer: I’m not affiliated with RedPanda in any way. I just stumbled upon their website when looking for the book.
I'm starting a webinar series about SQL Server indexing with the fine folks of MSSQLTips.com.…
A while ago I blogged about a use case where a pipeline fails during debugging…
Quite the title, so let me set the stage first. You have an Azure Data…
At Saturday the 21st of February I'm presenting an introduction to dimensional modelling at dataMinds…
I'm not trying to start up a debate whether you should use tabs or spaces…
The Power BI Enhanced Report Format (PBIR) will soon become the default, and that's a…
{kind=link}
View Comments
Joe Reis has a Subtack of same name, and another one called Practical Data Modeling that a few Microsoft Fabric types are in. I didn't finish this book, mostly searching for "Kimball". It's okay, my major problem with most data books is they saw Kimball is bottom-up and Inmon top-down, when that's not fully accurate. And equating Gold layer with aggregates, where I see aggregates in a dimensional star schema model as usually for performance or for matching grain.
Hi Donald,
thanks for the substack references, I will check them out!
Yeah, the deal with most data engineering books is that their focus isn't really on data modelling, so they don't spend much time on Kimball/Inmon, so you get an abbreviated form of what they stand for.
You have a point with aggregates, I only do them for matching grain. Power BI is there to do the aggregation for me :)