When working in business intelligence, data engineering or data in general, there are some “mantras” that are being adopted by the larger community as “best practices”. For example, I shout “STAR SCHEMA ALL THE THINGS” anywhere I can, because a star schema is the most optimal way to design your model in Power BI. We also have Matthew Roche‘s Maxim of Data Transformation:
Data should be transformed as far upstream as possible, and as far downstream as necessary.
It basically means you should try to do a data transformation as early in the process as possible (for example in the SQL query selecting data from the source, or in the data warehouse), rather than in Power Query or in DAX. Only move it up into the chain if it’s not possible (for example a dynamic median calculation, which can only be done by a DAX measure).
In this blog post I’ll talk about another of those rules/mantras/patterns/maxims:
build once, add metadata
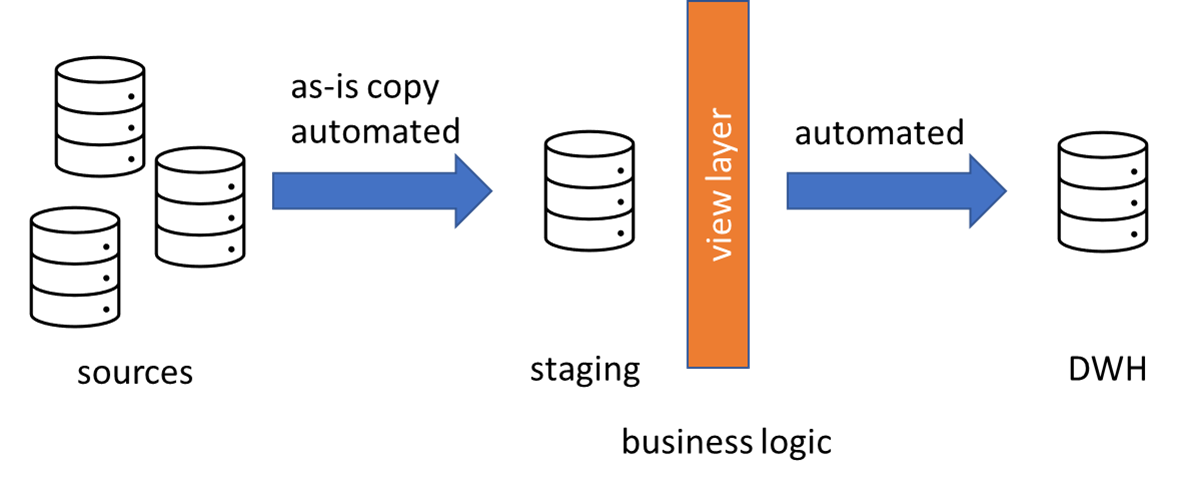
I’m not sure if I’m using the right words (metadata-driven framework is also a good name), I heard something similar in a session by Spark enthusiast Simon Whiteley. He said you should only write code once, but make it flexible and parameterized, so you can add functionality just by adding metadata somewhere. A good example of this pattern can be found in Azure Data Factory; by using parameterized datasets, you can build one flexible pipeline that can copy for example any flat file, doesn’t matter which columns it has. I have blogged about this:
You build your pipeline once, and if you want to add another flat file, you just enter some metadata into table.
You can do the same when loading data from a database: you just keep track of a metadata table (or you can just use INFORMATION_SCHEMA.TABLES if the source database supports it) and you loop over it to fetch the data of all those tables.
The pattern has become more popular with the “rise of data engineering”, because it typically involves more code and it’s easier to do such things when you can write code around it. But if you think about it, we’ve been implementing this pattern for quite some time. A few examples:
So what is the point of this blog post? First, to point out the obvious time savings you can have after you’ve wrote your solution. Want to load an extra flat file, just add a line into a table and start your pipeline. Done. Second, when you automate a pattern, you’re 100% sure data is going to be handled in always the same way. No exceptions, and thus easier to debug. Also, when you want to make a change, you can do it in one single place, instead of updating multiple packages/procedures.
Take a look at your data pipelines and your data warehouses, and ask yourself if you’re writing code that often looks the same. Maybe it’s a good opportunity to automate something. Thoughts? Let me know in the comments!
I'm starting a webinar series about SQL Server indexing with the fine folks of MSSQLTips.com.…
A while ago I blogged about a use case where a pipeline fails during debugging…
Quite the title, so let me set the stage first. You have an Azure Data…
At Saturday the 21st of February I'm presenting an introduction to dimensional modelling at dataMinds…
I'm not trying to start up a debate whether you should use tabs or spaces…
The Power BI Enhanced Report Format (PBIR) will soon become the default, and that's a…
{kind=link}
{kind=link}
View Comments
Amazing post. I just had this conversation.
Hi Keon
Great post, thanks.
Will appreciate if you can share any resources you have on using metadata-driven framework for SSIS solutions with me.
Hi,
for SSIS you need to check out the BIML framework:
https://www.mssqltips.com/sqlservertutorial/9089/introduction-to-the-biml-language/
You can also view an introduction webinar about the topic here:
https://www.mssqltips.com/sql-server-video/704/introduction-to-biml-generating-your-ssis-packages-from-scratch/