We’re reading in some JSON files in Azure Data Factory (ADF), for example for a REST API. We’re storing the data in a relational table (SQL Server, Azure SQL DB…). The data volume is low, so we’re going to use a Copy Data activity in a pipeline, rather than a mapping data flow (or whatever they’re called these days). The reason why I specifically mention this assumption is that a data flow can flatten a JSON, while a Copy Data activity it needs a bit more work.
A Copy Data activity can – as it’s name gives away – copy data between a source and a destination (aka sink). In many cases, ADF can map the columns between the source and the sink automatically. This is especially useful when you’re building metadata-driven parameterized pipelines. Meta-what? Read this blog post for more info: Dynamic Datasets in Azure Data Factory.
The problem with JSON is that it is hierarchical in nature, so it doesn’t map that easily to a flattened structure, especially if there’re nested lists/arrays/whatevers. So you would need to specify an explicit mapping with a collection reference, like the one in this screenshot:
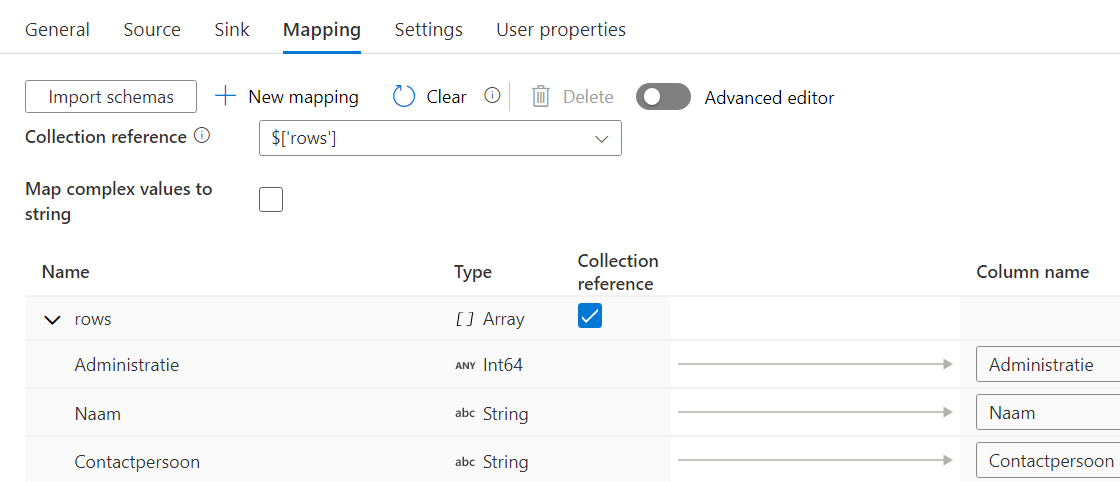
But if you need to import dozens of JSONs, this would mean a separate Copy Data activity for each JSON. Ugh, we don’t want that because that’s a lot of work. Luckily, there’s an option to specify a mapping with dynamic content (in other words, it can be parameterized):
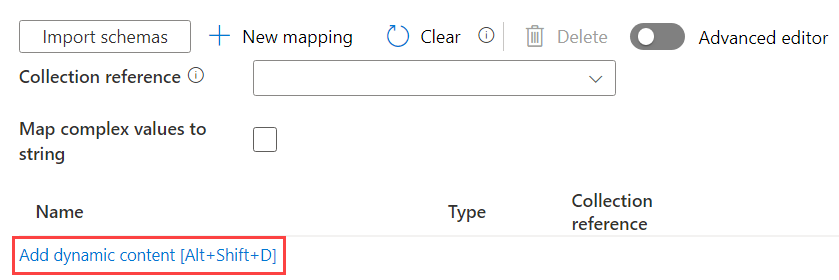
The mapping between the source and the sink columns needs to be specified using … JSON of course 🙂 The official docs explain how it should look like. In my case, I made a couple of assumptions:
- the destination table has already been created (it’s better this way, because if you let ADF auto-create it for you, you might end up with a table where all the columns are NVARCHAR(MAX))
- the column names from the source and the sink are exactly the same. Notice the emphasis on “exactly”. This means casing, but also white space and other shenanigans. If it’s not the case, ADF will not throw an error. It will just stuff the column it can’t map with NULL values.
- it’s OK if there are columns in the source or the sink that don’t exist on the other side. They just won’t get mapped and are thus ignored.
I wrote a little script that will read out the metadata of the table and translate it to the desired JSON structure. It uses FOR JSON, so you’ll need to be on SQL Server 2016 or higher (compat level 130). If you’re on an older version, read this blog post by Brent Ozar.
CREATE FUNCTION [dbo].[Get_JSONTableMapping](@TableName VARCHAR(250))
RETURNS TABLE
AS
RETURN
SELECT jsonmapping = '{"type": "TabularTranslator", "mappings": ' +
(
SELECT
'source.path' = '[''' + IIF(c.[name] = 'Guid','GUID_regel',c.[name]) + ''']'
-- ,'source.type' = m.ADFTypeDataType
,'sink.name' = c.[name]
,'sink.type' = m.ADFTypeDataType
FROM sys.tables t
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.all_columns c ON c.object_id = t.object_id
JOIN sys.types y ON c.system_type_id = y.system_type_id
AND c.user_type_id = y.user_type_id
JOIN etl.ADF_DataTypeMapping m ON y.[name] = m.SQLServerDataType
WHERE 1 = 1
AND t.[name] = @TableName
AND s.[name] = 'src'
AND c.[name] <> 'SRC_TIMESTAMP'
ORDER BY c.column_id
FOR JSON PATH
) + ',"collectionreference": "$[''rows'']","mapComplexValuesToString": true}';
It returns output like this:
{
"type": "TabularTranslator",
"mappings": [
{
"source": {
"path": "['Column1']"
},
"sink": {
"name": "Column1",
"type": "Int32"
}
},
{
"source": {
"path": "['Column2']"
},
"sink": {
"name": "Column2",
"type": "String"
}
}
],
"collectionreference": "$['rows']",
"mapComplexValuesToString": true
}
Keep in mind that the collection reference is specific for my use case (REST API reading data from the AFAS ERP system btw). You probably will need to change it to accommodate it for your JSON. The function also uses a mapping table which maps the SQL Server data types to the data types expected by ADF (as explained in the official docs I linked to earlier).

The full table in SQL INSERT statements:
CREATE TABLE #temptable ( [ADFTypeMappingID] int, [ADFTypeDataType] varchar(20), [SQLServerDataType] varchar(20) ) INSERT INTO #temptable ([ADFTypeMappingID], [ADFTypeDataType], [SQLServerDataType]) VALUES ( 1, 'Int64', 'BIGINT' ), ( 2, 'Byte array', 'BINARY' ), ( 3, 'Boolean', 'BIT' ), ( 4, 'String', 'CHAR' ), ( 5, 'DateTime', 'DATE' ), ( 6, 'DateTime', 'DATETIME' ), ( 7, 'DateTime', 'DATETIME2' ), ( 8, 'DateTimeOffset', 'DATETIMEOFFSET' ), ( 9, 'Decimal', 'DECIMAL' ), ( 10, 'Double', 'FLOAT' ), ( 11, 'Byte array', 'IMAGE' ), ( 12, 'Int32', 'INT' ), ( 13, 'Decimal', 'MONEY' ), ( 14, 'String', 'NCHAR' ), ( 15, 'String', 'NTEXT' ), ( 16, 'Decimal', 'NUMERIC' ), ( 17, 'String', 'NVARCHAR' ), ( 18, 'Single', 'REAL' ), ( 19, 'Byte array', 'ROWVERSION' ), ( 20, 'DateTime', 'SMALLDATETIME' ), ( 21, 'Int16', 'SMALLINT' ), ( 22, 'Decimal', 'SMALLMONEY' ), ( 23, 'Byte array', 'SQL_VARIANT' ), ( 24, 'String', 'TEXT' ), ( 25, 'DateTime', 'TIME' ), ( 26, 'String', 'TIMESTAMP' ), ( 27, 'Int16', 'TINYINT' ), ( 28, 'GUID', 'UNIQUEIDENTIFIER' ), ( 29, 'Byte array', 'VARBINARY' ), ( 30, 'String', 'VARCHAR' ), ( 31, 'String', 'XML' ), ( 32, 'String', 'JSON' ); DROP TABLE #temptable
So we can execute this function inside a Lookup activity to fetch the JSON metadata for our mapping (read Dynamic Datasets in Azure Data Factory for the full pattern of metadata-driven Copy Activities).
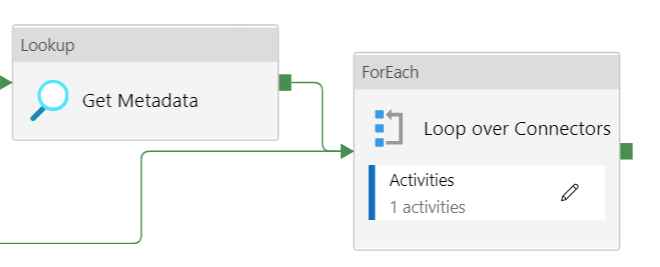
In the mapping configuration tab of the Copy Data Activity, we can now create an expression referencing the output of the Lookup activity.
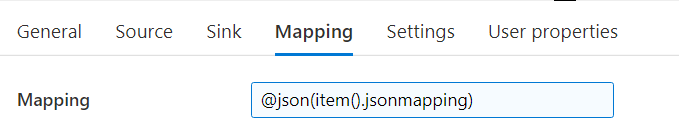
For easy copy paste:
@json(item().jsonmapping)
The item() function refers to the current item of the array looped over by the ForEach activity:
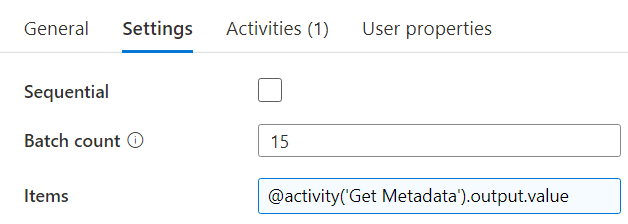
We need to wrap the expression of the mapping in the @json function, because ADF expects an object value for this property, and not a string value. When you know run the pipeline, ADF will map the JSON data automatically to the columns of the SQL Server table on-the-fly.
Note: there are other options as well to load JSON into a SQL Server database. You can dump the JSON into blob storage and then shred it using an Azure Function or Azure Logic App for example, or you can dump it into a NVARCHAR(MAX) column in a staging table and then use SQL to shred the JSON. Or use ADF data flows. I prefer the option from this blog post because the code complexity is very low and it’s dynamic. Just add a bit of metadata, create your destination table and you’re done.
------------------------------------------------
Do you like this blog post? You can thank me by buying me a beer 🙂
awesome . just what I was looking for.i
Wish the ADF could do table mapping from REST automtically like it does for table to table
Great, glad it was useful.
Automatic mapping would be great, but the JSON would have to be really simple.
But JSON is hierarchical, while tables are flat. Once you have multiple nested arrays and other shenanigans, it becomes quite difficult to map.
Recently I had to ditch ADF because the mapping was just too hard to do, and I had to use OPENJSON in SQL instead.
Yeah I was just trying to be lazy and not wating to go to REST->flatFile ->Table which might be better suited for complex jsons. But you are right if the jsons are simple and have that tabular structure to flatten , this is much simpler.
My JSON Files are nested within 1 Group:
{ “value”: [ *** Multiple attributes per entity ]}}
The ADF Copy activity will only pull the first entity because it maps like this. $[‘value’][0][‘PersonId’] It doesn’t appear to support a wildcard for all instances of the entity. Am I stuck using Mapping Data Flows?
Hi David,
is it possible to give a json with some sample data (but with the exact same structure as you’re using)?
Also, it’s possible to get it to work I think by removing the [0]: $[‘value’][‘PersonId’]
Hi David, Thanks for the great article. Clearly outlines the steps required. I’d like to connect about an issue I am experiencing where the landing data in my SQL table is not having the defined column definitions of the JSON I provide as the dynamic content. The columns are all inserted to the SQL table as nvarchar(max) a horrible column definition.
Hi John,
what’s the issue exactly? Are you letting ADF create the table? Because that will result in NVARCHAR(MAX) columns.
Koen
Opps, sorry Koen, mix-up the author with a commenter.
Yes, ADF is creating the table.
I am using a COPY Activity with “Auto Create Table” set, in the mapping I’m providing the Dynamic JSON as you have pointed out above, however with out the two last elements :
“collectionreference”: “$[‘rows’]”, “mapComplexValuesToString”: true
As it would appear from MS Docs that those are required for source datasets that are in a non tabular form.
Perhaps my understanding of the copy activity is wrong. Will it not use the Dynamic Mapping JSON I provide to create the destination columns?
The json mapping is used so ADF knows how to parse the JSON file to find the input columns. The mapping then dictates which input column corresponds with which columns of the destination table. ADF can use the mapping to determine the column names of the destination table, but not the data types. Since JSON is text, ADF will just use NVARCHAR(MAX) for each column. I typically create my tables upfront, instead of letting ADF create them.
Sometimes ADF can be so frustrating. Its so powerful, yet some simple things are just so complicated to do.
Koen, thanks, Do you think a PreSQL Script in the copy operation which builds the table dynamically then copies the data to the Just built table will work?
I haven’t tried it, but it might work.
Well I wrote the code to create the table dynamically before the SINK writes to the destination. Without using the TubularTranslator SQL will just cast the data as it comes in. So there really was no need for the exercise of converting it in the ADF Memory Stream.
In short if you want to have nicely formatted data types (at least in a SQL SINK) Create the table first with a preSQL Script, then let ADF Copy to that created well defined SINK destination.
Still, good article. lots to chew on here.
@Dan How did you do it? 🙂 Im also looking to create the tables upfront so i can use the solution in generic. AFAS gives you a json file whit the columns and data types. I would like to use that to create te tables and columns. For now i have a second foreach with data copy to get the metadata columns from the getconnector and would like to insert that as a table to the sql.
@Dan:
Just curious: Why would you write code to create the table dynamically before the SINK writes to the destination? You just have to create each table once with the correct field names and data types.
So Why did you create code to create the tables dynamically?
And I know you can get the field/column names from the JSON files, but how to determine dynamically what data types you need for all fields in all tables?
Hello Hennie, The reason why I wanted to create a dynamic table. My ADF Pipeline is more of a generic solution where you can point the pipeline to many new sources and it will automatically create the destination sink tables. This is particularly useful if your source has many tables, but you only want to copy over a few to a Reporting DB. In my case, We are reading from a CDK Data source, with over 120 tables, and the business only needs to have access to a handful at the moment with plans to expand the scope of data at a later time. The ADF pipeline reads a configuration table for the tables to pull from the source and how to write it to the destination. So, as their requirements expand, all I need to do is add a row to the configuration table, and the pipeline will loop over the configurations pulling the sources and sinking to the destinations. Hope that makes sense.
Hi Koen,
In this article you wrote “So we can execute this function inside a Lookup activity to fetch the JSON metadata for our mapping ”
I created the mappings table and the function in Azure SQL succesfully (inside my database), how to execute this function in the lookup activity? I see I can execute for example a SQL query or a stored procedure, but how to execute the function?
I found out myself…. Just use the function in a select query….
Hi, I was on holiday, hence the late reply. Since it’s a table valued function, you can use it in the FROM clause of a SELECT query, or with the APPLY operator (which is like a JOIN for functions).
Hi, Now I have another problem in the copy activity (within the for each)
When I debug the afd, I get next error from the copy activity:
ErrorCode=AdlsGen2OperationFailed,’Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=ADLS Gen2 operation failed for: Operation returned an invalid status code ‘Conflict’. Account: ‘storageergonbidatalake’. FileSystem: ‘afas’. Path: ‘{“jsonmapping”:”{/”type/”: /”TabularTranslator/”, /”mappings/”: [{/”source/”:{/”path/”:/”[‘Geblokkeerd’]/”},/”sink/”:{/”name/”:/”Geblokkeerd/”,/”type/”:/”Boolean/”}},{/”source/”:{/”path/”:/”[‘FacilitairCategorieCode’]/”},/”sink/”:{/”name/”:/”FacilitairCategorieCode/”,/”type/”:/”String/”}},{/”source/”:{/”path/”:/”[‘FacilitairCategorie’]/”},/”sink/”:{/”name/”:/”FacilitairCategorie/”,/”type/”:/”String/”}},{/”source/”:{/”path/”:/”[‘KDR’]/”},/”sink/”:{/”name/”:/”KDR/”,/”type/”:/”String/”}},{/”source/”:{/”path/”:/”[‘Kostendrager’]/”},/”sink/”:{/”name/”:/”Kostendrager/”,/”type/”:/”String/”}}],/”collectionreference/”: /”$[‘rows’]/”,/”mapComplexValuesToString/”: true}”}.JSON’. ErrorCode: ‘PathIsTooDeep’. Message: ‘This operation is not permitted as the path is too deep.’. RequestId: ‘c3d1959f-101f-0052-1048-a79646000000’. TimeStamp: ‘Wed, 03 Aug 2022 14:51:06 GMT’..,Source=Microsoft.DataTransfer.ClientLibrary,”Type=Microsoft.Azure.Storage.Data.Models.ErrorSchemaException,Message=Operation returned an invalid status code ‘Conflict’,Source=Microsoft.DataTransfer.ClientLibrary,’
Is it possible to send a sample JSON file (with fake data of course)?
..I solved it… apparently I had the wrong source and sink settings: item(), where it should be:
@pipeline().parameters.
Correction on previous post: source and sink of copy should be @pipeline().parameters.ParameterName
Hi Koen,
I have another question: Do you first copy from REST tot .JSON files, and then copy from json files to SQl tables with the dynamic mapping? Or do you copy directly from REST to SQL table?
What is the whole picture from REST to SQL Table? In this article you use a screenshot from the Lookup and the ForEach, but I would like to know what are the steps before it, where do the green arrows come from 🙂
Hi Hennie,
in my case I directly copy from the REST API endpoint to a SQL table.
If the JSON was too complex to map directly, I would choose to write to a JSON first, import this into a SQL table as a whole and then shred it with SQL. Luckily, this was not necessary.
I think the green arrows come from a script activity (to truncate the staging tables) and from a Azure Keyvault to retrieve an access token for the REST API. There’re not that relevant for this blog post 🙂
Koen
Hi Koen,
Thank you for the quick reply. In this article you use a lookup to execute the function (in a query), but how do you use the lookup twice? I have a lookup which queries a list of AFAS connectors (it works), and then there is this lookup to execute the mapping function. Now in my situation The foreach refers to the connector lookup. But then I cannot refer to the mapping metadata lookup…
You can use CROSS APPLY in the query to get your AFAS connectors to join the output of the function to the result set. Something like this:
SELECT *
FROM dbo.myAFASConnectors a
CROSS APPLY dbo.Get_JSONTableMapping(a.tablename) j
This will get everything into one single result set, which you can loop over using the foreach.
Hope this helps,
Koen
Hi Koen,
Thanks for the elaborate explanations on how to setup a dynamic pipeline to AFAS.
I am however getting stuck on implementing the function which retrieves the mapping details. I have not yet added the neccessary tables to my SQL DB (despite your recommendation) since that is something I hoped to do through this method to avoid having to do it manually and having to assign mapping for each table.
Do you retrieve the mapping details from your already stored tables in your SQL DB, or do you make the function connect through the getconnector to retrieve the mapping from AFAS? My SQL knowledge isn’t very advanced, so please excuse my lack of comprehension of your script :).
Thanks again for your help!
Hi Joe,
I get the metadata from the AFAS getconnector. Each getconnector has a metadata endpoint as well. The relative URL is something like this: /metainfo/get/mygetconnector. This will give you the entire list of columns and their data types. You can use this with some dynamic SQL to generate the tables for your database.
Regards,
Koen
Hi Koen,
Can you give an example how to do this? I would like to use the connector metdata endpoint to create my tables upfront. Tryed some openjson etc. But im getting stuck now. Thanks!
Hi Michiel,
I read out the metadata endpoint with ADF in a copy data activity. I map the json data to a relational table over there in the mapping pane. This way you won’t need openjson, you can directly start from a nice metadata table and use dynamic sql to construct the create table statement.
Regards,
Koen
HI Koen,
Thnx for the tip. Im trying to do what you say, but im getting stuck on the pre sql script. I have the metadata from AFAS and used the fields in mapping. The metadata will depend on the fields that are in the getconnector. I want to make it as flexibel as possible. For now there are a couple offields with the properties like label, type, lenght etc. Those fields i mapped. But how do i use the variables in the sql script and further more, how to do it dynamically with the number of fields that can be different on the getconnector? If i use $item it will only get the connector names from the foreach.My goal is to create a dynamic pipeline so i can build getconnectors en run pipeline to create tables with data for reporting in powerbi.
Example output:
“fields”: [
{
“id”: “Instuurdatum”,
“fieldId”: “U001”,
“dataType”: “date”,
“label”: “Instuurdatum”,
“length”: 0,
“controlType”: 8,
“decimals”: 0,
“decimalsFieldId”: “”
},
{
“id”: “Omschrijving”,
“fieldId”: “U002”,
“dataType”: “string”,
“label”: “Omschrijving”,
“length”: 50,
“controlType”: 1,
“decimals”: 0,
“decimalsFieldId”: “”
},
{
“id”: “Onderwerp”,
“fieldId”: “U003”,
“dataType”: “string”,
“label”: “Onderwerp”,
“length”: 255,
“controlType”: 1,
“decimals”: 0,
“decimalsFieldId”: “”
},
{
“id”: “Omschrijving_2”,
“fieldId”: “U004”,
“dataType”: “string”,
“label”: “Omschrijving”,
“length”: 80,
“controlType”: 1,
“decimals”: 0,
“decimalsFieldId”: “”
},
{
“id”: “Omschrijving_3”,
“fieldId”: “U006”,
“dataType”: “string”,
“label”: “Omschrijving”,
“length”: 50,
“controlType”: 1,
“decimals”: 0,
“decimalsFieldId”: “”
},
{
“id”: “Omschrijving_4”,
“fieldId”: “U007”,
“dataType”: “string”,
“label”: “Omschrijving”,
“length”: 80,
“controlType”: 1,
“decimals”: 0,
“decimalsFieldId”: “”
},
{
“id”: “FBO_-_type_melding_code”,
“fieldId”: “U005”,
“dataType”: “string”,
“label”: “FBO – type melding code”,
“length”: 20,
“controlType”: 1,
“decimals”: 0,
“decimalsFieldId”: “”
},
{
“id”: “FBO_-_type_melding”,
“fieldId”: “U008”,
“dataType”: “string”,
“label”: “FBO – type melding”,
“length”: 100,
“controlType”: 1,
“decimals”: 0,
“decimalsFieldId”: “”
},
{
“id”: “FBO_-_Categorie_code”,
“fieldId”: “U009”,
“dataType”: “string”,
“label”: “FBO – Categorie code”,
“length”: 20,
“controlType”: 1,
“decimals”: 0,
“decimalsFieldId”: “”
},
{
“id”: “FBO_-_Categorie”,
“fieldId”: “U010”,
“dataType”: “string”,
“label”: “FBO – Categorie”,
“length”: 100,
“controlType”: 1,
“decimals”: 0,
“decimalsFieldId”: “”
},
{
“id”: “Nummer”,
“fieldId”: “U011”,
“dataType”: “string”,
“label”: “Nummer”,
“length”: 15,
“controlType”: 5,
“decimals”: 0,
“decimalsFieldId”: “”
},
{
“id”: “Naam”,
“fieldId”: “U012”,
“dataType”: “string”,
“label”: “Naam”,
“length”: 255,
“controlType”: 1,
“decimals”: 0,
“decimalsFieldId”: “”
},
{
“id”: “Type_dossieritem”,
“fieldId”: “U013”,
“dataType”: “int”,
“label”: “Type dossieritem”,
“length”: 9,
“controlType”: 5,
“decimals”: 0,
“decimalsFieldId”: “”
},
{
“id”: “Org_id”,
“fieldId”: “U014”,
“dataType”: “string”,
“label”: “Org id”,
“length”: 15,
“controlType”: 5,
“decimals”: 0,
“decimalsFieldId”: “”
}
]
Hope you can help or give a tip. Thnx!
Michiel
Hi Michiel,
this is how I map the output of the meta REST API to the SQL table storing the metadata:
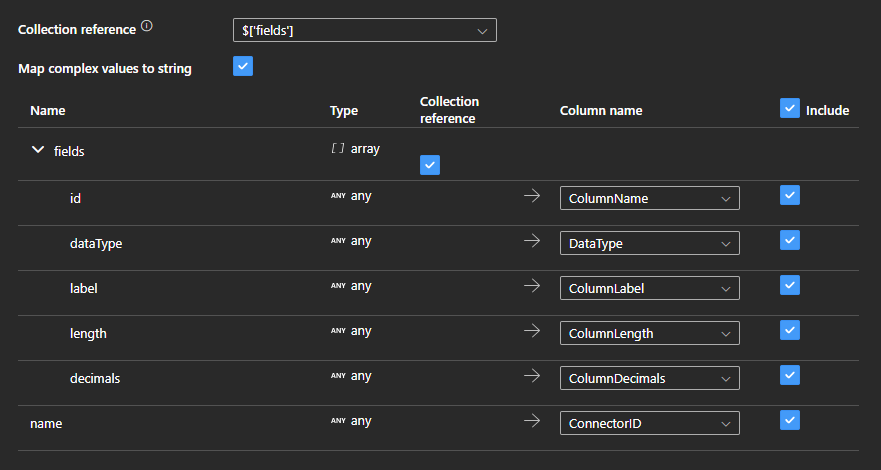
This should store the metadata of a getconnector into the table. Then you can write dynamic SQL to create the DDL statement for that table.
Hi Koen,
I have a one scenario
I have json file…like below…
[
{
“sourceBaseURL”:”https://gitlab.com”,
“sourceRelativeURL”:”vvv.2012/abc-p/-/raw/main/o1.csv”,
“sinkFileName”:”o1.csv”
},
{
“sourceBaseURL”:”https://gitlab.com”,
“sourceRelativeURL”:”bbb.2012/abc-p/-/raw/main/o2.csv”,
“sinkFileName”:”o2.csv”
},
{
“sourceBaseURL”:”https://gitlab.com”,
“sourceRelativeURL”:”gggv.2012/abc-p/-/raw/main/o3.csv”,
“sinkFileName”:”o3.csv”
}
]
—–*****——-
I have to read the json file and have to apply the url or relative url by dynamically to get the all files with respect to relative url in one pipeline…
Could you please help for this scenario…
Personally I would rather use a Logic App to do this.
https://stackoverflow.com/questions/49311455/azure-logic-apps-download-file-from-url
(or maybe an Azure Function)
If you really want to do this in ADF, you can try the following:
https://www.cloudmatter.io/post/azure-data-factory-load-file-from-http-api-to-data-lake-in-10-minutes
Hello,
I use this dynamic mapping with succes, but how to handle errors? For example, if some values in the source are too long (30 characters) and the copy activity writes this to a field with length 25, how to configure error handling so I can see this error in a CSV?
Hi Hennie,
I haven’t tried it myself, but according to the documentation it seems to be possible to log skipped error rows:
https://learn.microsoft.com/en-us/azure/data-factory/copy-activity-fault-tolerance#copying-tabular-data
Hi Koen, Thanks for the article. I tried to simulate your approach but I’m having trouble. I am receiving an array of nested JSONs from a REST API. I set the jsonmapping variable like yours and I set the index part of the variable like “$[‘results’][0][‘stage’]”. Then in the foreach activity, there is a set variable activity that replaces the [0] with loop index in the modifiedmapping variable, but a backslash is added before each double quote. When I use @json(variables(modifiedmapping)) in the copy activity mapping, it doesn’t copy.
if you wanted to also save the Collection reference objects $[rows] to another column in the same sink,
and end up with column1, column2, rows_data
How do you map to the Collection Reference?
The use case is the response is complex, so we expose a few key attributes and want to save the full complex JSON object in a single column.
In that case I typically just dump the entire JSON into one single column and then parse it with SQL. I haven’t done a partial parsing while still writing the entire JSON to a column, and I’m not sure it’s possible.