A while ago I had a little blog post series about cool stuff in Snowflake. I’m starting up a similar series, but this time for Microsoft Fabric. I’m not going to cover the basic of Fabric, hundreds of bloggers have already done that. I’m going to cover little bits & pieces that I find interesting, that are similar to Snowflake features or something that is an improvement over the “regular” SQL Server.
To kick off this series, I’m going to start with a feature that also exists in Snowflake: zero-copy cloning. The idea is that you create a copy of a table, but instead of actually copying the data, pointers are created behind the scenes that just point to the original data. This means creating a clone is a metadata-only operation and is thus very fast. If you make updates against your clone, they will be stored separately, so in all purposes it seems you created a brand new table. Except you didn’t.
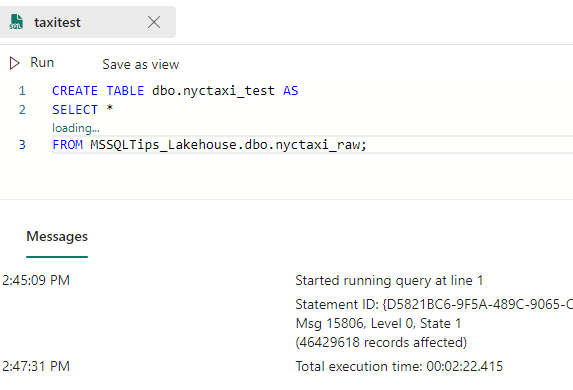
To illustrate this feature, I created a new table in my Fabric warehouse using the CTAS command.
CREATE TABLE dbo.nyctaxi_test AS SELECT * FROM MSSQLTips_Lakehouse.dbo.nyctaxi_raw;
This command copied about 46 million rows from my lakehouse into the data warehouse. This took roughly 2 minutes and 22 seconds. I’m using the smallest Fabric capacity available (F2), so I’m quite pleased with the performance.
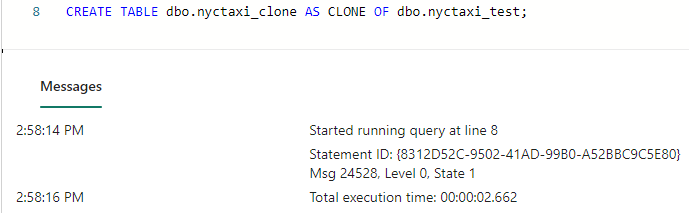
Then I issued a CREATE TABLE AS CLONE command, to create a new clone.
CREATE TABLE dbo.nyctaxi_clone AS CLONE OF dbo.nyctaxi_test;
As you can see, this executes almost immediately:
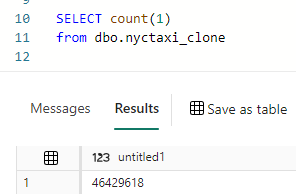
You can query this table like any other table:
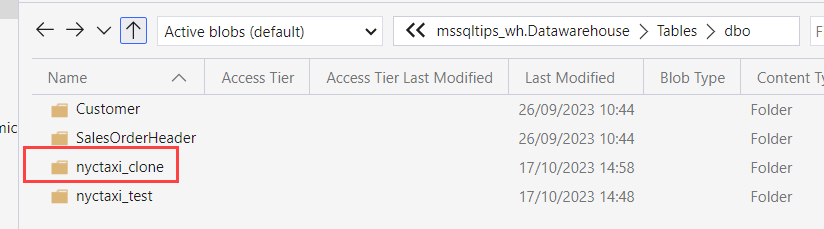
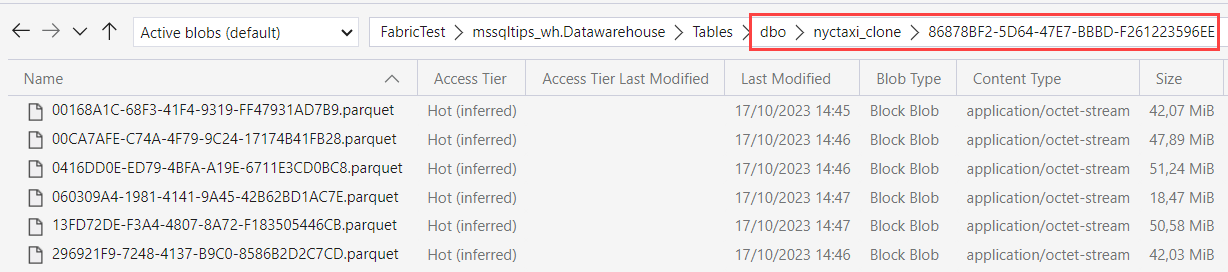
If we take a peek behind the curtains using Azure Storage Explorer (learn more about how you can connect to your OneLake storage using Storage Explorer here), we can see a table has been added:
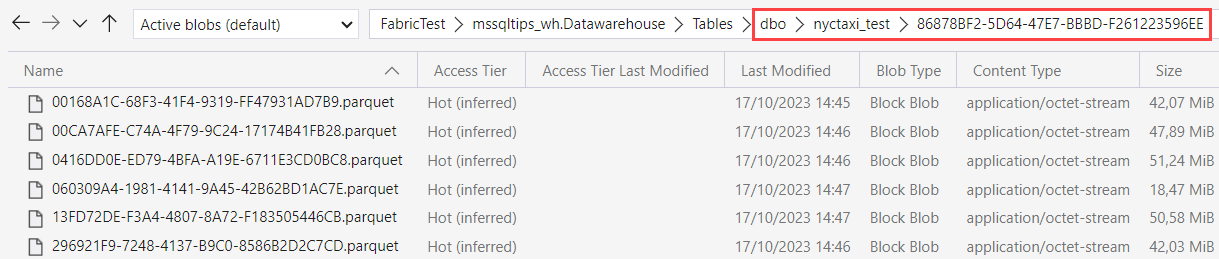
If we take a look inside that folder, we can find a whole bunch of parquet files! Whoah, I thought this was zero-copy?
Actually it’s the Fabric endpoint that is playing tricks with us. If we go look at the Parquet files of the original table, we will find that these are the exact same files (same GUIDs in the name, same modified date etc).
Azure Storage Explorer is following the pointers as well, making it look like there’s data at two different places, but in reality the data is only stored once.
Unfortunately, we can only clone tables at the time of writing. Snowflake supports the cloning of entire schemas and databases (with all objects inside them), which is a very useful feature for setting up testing environments for example. But, with the power of stored procs available in the Fabric data warehouse, you can probably code your way around this.
I'm starting a webinar series about SQL Server indexing with the fine folks of MSSQLTips.com.…
A while ago I blogged about a use case where a pipeline fails during debugging…
Quite the title, so let me set the stage first. You have an Azure Data…
At Saturday the 21st of February I'm presenting an introduction to dimensional modelling at dataMinds…
I'm not trying to start up a debate whether you should use tabs or spaces…
The Power BI Enhanced Report Format (PBIR) will soon become the default, and that's a…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}