Whoa whoah. Aren’t you supposed to increase your data flow buffer size in order to speed up your packages? If you have enough memory and you can process more rows at the same time because your buffer is larger, that’s what we want, right? Yes, this is confirmed by the old blog post Adjust buffer size in SSIS data flow task by the SQL Server Performance Team. But this is only true when your source is fast enough to fill those buffers. If you have very large buffers, the remainder of the data flow is just waiting for the slow source to fill a buffer, which is just time going to waste.
Rob Farley (blog | twitter) describes the concept in his excellent blog post The SSIS tuning tip that everyone misses. Basically, it’s about filling your buffers with data as soon as possible, so other data flow tasks can start working on it. Rob achieved his goal by specifying a query hint, but you can do the same by making your buffers smaller. Because, a smaller buffer takes less time to be filled with data and can be passed on the data flow much quicker. Jamie Thomson (blog | twitter) describes the effect in his blog post SSIS: A performance tuning success story (edit: this very old blog post link is dead). I also encountered a similar story in a forum thread.
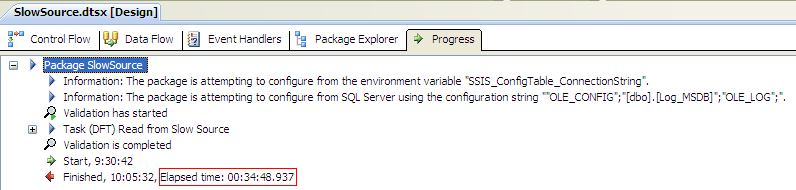
I’ll share one of my success stories as well. In my recent Oracle migration, I was transferring a table from Oracle to SQL Server using SSIS. The table wasn’t really large, only about 90,000 rows, but one column contained XML files. These were stored in the Oracle database as a CLOB column (Character Large Object) and in SQL Server as a NVARCHAR(MAX) column. Some of these XML could be quite large, some up to 50MB. When I ran my package using the default settings, 10MB for DefaultBufferSize and 10,000 for DefaultBufferMaxRows, I had to stare a long time at a yellow source, without any data being transferred.
After almost 35 minutes, the package finished loading all the rows into SQL Server.
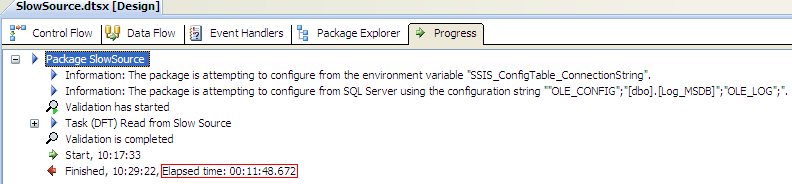
However, when I changed the DefaultBufferMaxRows to 500, the package finished in a mere 11 minutes!
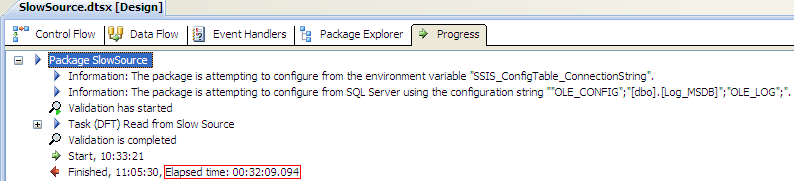
To make sure this incredible speed-up wasn’t the result of any caching on the source, I ran the package again with the default settings:
Possible caching seems to nibble 2 minutes off (or it just might be coincidence), but it isn’t responsible for making the packages run three times as fast.
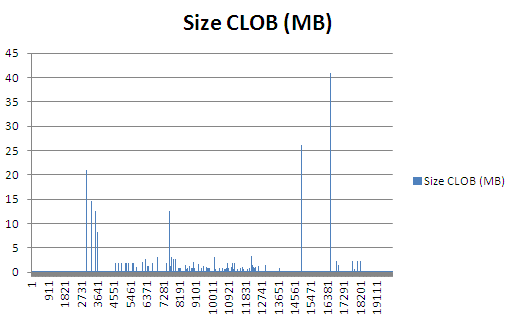
Why the big difference? I created an Excel graph displaying the size of the CLOB column for the first 20,000 rows, which roughly equals 2 buffers when the default settings are used. I used the function DBMS_LOB.getlength to get the number of characters in a particular XML file in the CLOB column. Assuming every character equals one byte, this is the same as the size in bytes. I’m educated as an engineer, so g = 10, Π = 3 and my CLOB columns contains only singe byte characters and no multi-byte characters
We can see that around row 2800 a 20 megabyte CLOB value shows up, followed by several other large XML files. In the second buffer we have even larger XML files, one of 25MB and one of 40MB. Needless to say, it takes a while for SSIS can fill a buffer with this large data. Once a buffer is full, it is passed immediately to the destination. It’s possible the next buffer is very quickly populated if the next rows contain only XML files of a few kilobytes large. But because the destination is still processing the previous large buffer, we get an effect called pipeline backpressure, which is described in detail by Todd McDermid (blog | twitter) in his blog post What is Pipeline Backpressure?. When we combine these two effects – a slow source and an occasional pipeline backpressure – we get a very slow package.
When we use a much smaller buffer – 500 rows in my case – the source can already fill up a few buffers before the first large XML is reached. This keeps the destination busy while the source processes these big rows. Because the larger XML files are uniformly distributed over the table, we can take full advantage of this effect, cutting the total package runtime to one third.
Conclusion
When dealing with a slow source, it might be beneficial to lower the size of the data flow buffer in order to get better performance. Don’t do this all the time! Most of the time the default settings are good enough and if the source is fast you might benefit from bigger buffers. As always, test test test and then put it in production.
I'm starting a webinar series about SQL Server indexing with the fine folks of MSSQLTips.com.…
A while ago I blogged about a use case where a pipeline fails during debugging…
Quite the title, so let me set the stage first. You have an Azure Data…
At Saturday the 21st of February I'm presenting an introduction to dimensional modelling at dataMinds…
I'm not trying to start up a debate whether you should use tabs or spaces…
The Power BI Enhanced Report Format (PBIR) will soon become the default, and that's a…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}