At my recent project I’ve had the pleasure of working with
Snowflake database (no, not the modelling technique) for the first time. Snowflake is a native cloud data warehouse, which means it is built for the cloud from the ground up. It’s not a conversion of an existing database or appliance into a cloud model; Snowflake is only available in the cloud. In this blog post, I gather some of my impressions – some negative, most positive – from working with Snowflake for about 3 months now.
Let’s start with the positive.
- Snowflake is a really scalable database. Storage is virtually limitless, since the data is stored on blob storage (S3 on AWS and Blob Storage on Azure). The compute layer (called warehouses) is completely separated from the storage layer and you can scale it independently from storage.
- It is really easy to use. This is one of Snowflake’s core goals: make it easy to use for everyone. Most of the technical aspects (clustering, storage etc) are hidden from the user. If you thought SQL Server is easy with it’s “next-next-finish” installation, you’ll be blown away by Snowflake. I really like this aspect, since you have really powerful data warehousing at your finger tips, and the only thing you have to worry about is how to get your data into it. With Azure SQL DW for example, you have to about distribution of the data, how you are going to set things up etc. Not here.
- Scaling up and scaling out is straight forward with the warehouses. You create a warehouse with a certain size (XS, S, M, L, XL and so on). Query too slow? Just take a bigger warehouse size and the query goes faster. Too many concurrency? Scale out by creating multiple nodes in the same warehouse, so you can handle more queries at once. For each warehouse size, you pay a certain amount of credits per hour. The good part is that the warehouses scale almost linearly. If you have a small warehouse and the ETL processing takes one hour, you can scale up to a medium warehouse. The ETL will now take around half an hour. This means you pay the same amount, but your ETL is done twice as fast. You can configure warehouses to auto-shutdown to limit costs (how I wish every Azure product has this).
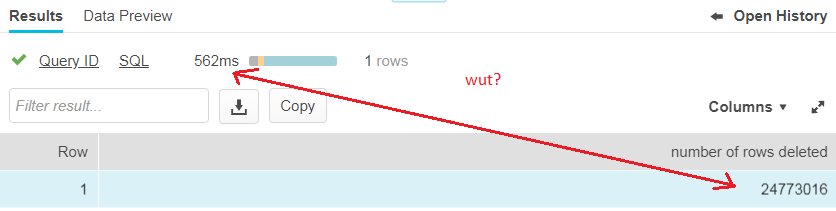
- Because of the way storage is structured (files on blob storage), every table is a temporal table. History is kept automatically (the duration depends on your license). Using time travel functionality, you can query every table and specify a point in time, which will return the data of the table as it was then. Accidentally run a DELETE without a WHERE clause? Query the table from 5 minutes back and retrieve your deleted data. No back-ups needed. Because of how this works, some queries are metadata-only operations. For example, in SQL Server, TRUNCATE TABLE is a metadata operation, which makes it extremely fast. In Snowflake you can have this behavior as well. I deleted 24 million rows of a table with 33 million rows (using DELETE with a WHERE clause). Those 24 million rows were just inserted before. This resulted in a metadata operation, which means the DELETE completed in less than a second. Amazing.
- The SQL language is ANSI compliant, which makes migrations easy. There are also some nice functions available which I kind of miss in SQL Server. For example, the UNDROP TABLE command. But also functions to work natively with unstructured data (such as arrays), regular expressions and so on. A really nice one is the IGNORE NULLS option for the lag/lead functions, which tells you to ignore NULL values in the window and just fetch the last non-null value. Amazeballs.
- You pay for what you use. For storage, you pay around $40/TB per month. Peanuts. For compute, you pay the credits associated for the warehouse you use. If you don’t use anything, you pay nothing. You are billed per second, with a one minute minimum once the warehouse starts.
- Depending on the query, it can be wicked fast. On an XS warehouse, I’ve inserted 36 million rows into a table in about half a minute. If you’re wondering, Snowflake is ACID compliant. Keep in mind it is a data warehouse. OLTP queries can be (much) slower compared with SQL Server or other relational databases. The best performance is observed with ELT scenarios and OLAP-type queries.
Some negative aspects:
- there is no client made by Snowflake itself. There’s no SQL Server Management Studio (or Operations Studio) equivalent. You need to use 3rd party tools which support Snowflake or ODBC connectors. Aqua Data Studio or DBeaver are some examples. You can connect to Snowflake with the browser and there you have worksheets where you can run SQL statements. But there’s no real intellisense. There’s a command-line interface though, for the die-hards among us.
- the products is quite new, so it is not as mature as some of its competitors. There are some minor glitches here and there, but the Snowflake teams seems to work hard to get those removed.
- there’s no real devops tooling. There’s no source control (yes, you have time travel, but it’s not the same). For a while, there were no stored procedures (they are now in preview). Automating scripts is harder and you probably are going to need other tools for that (for example, Python that runs your SQL scripts).
Alright, this was a quick blog post with some of my first impressions. Hopefully I can put more content out here when I’ve played more with the product.
{kind=link}
View Comments
Great article! Quick question... Your one comment mentioned you inserted 36 million records in half a minute. How did you do that? I’m assuming you had to generate CSV files and upload using snowSQL?
Hi Tony,
it was actual production data. The data was dumped into an S3 bucket as csv files (gzipped), which were then inserted into a landing zone table using a COPY INTO statement. The insert I'm talking about is loading data from the landing zone to another table using a regular INSERT INTO statement.