I have a metadata-driven ELT framework that heavily relies on dynamic SQL to generate SQL statements that load data from views into a respective fact or dimension. Such a task is well suited for generation, since the pattern to load a type 1 SCD, type 2 SCD or a fact table is always the same.
To read the metadata of the views, I use a couple of systems views, such as sys.views and sys.sql_modules. At some point, I join this metadata (containing info about the various columns and their data types) against metadata of my own (for example, what is the business key of this dimension). This all works fine in Azure SQL DB or SQL Server, but in my Fabric warehouse I was greeted with the following error:
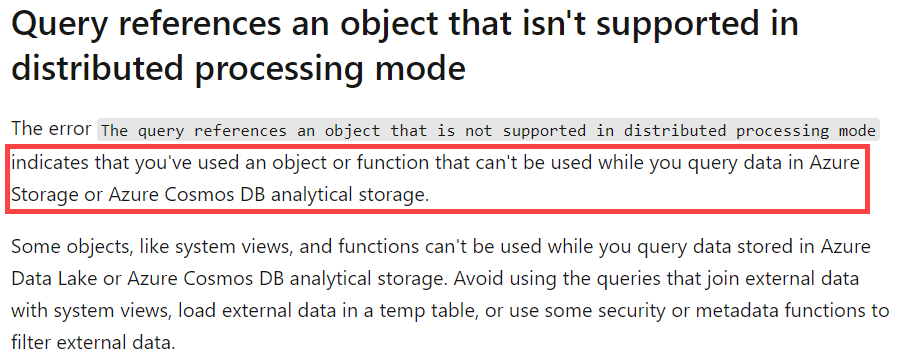
The query references an object that is not supported in distributed processing mode.
Okay, weird cryptic error that I never saw before. A quick search led me to a documentation page of Synapse Serverless SQL Pools (I guess there’s quite some similarity on how both technologies work).
Apparently, you cannot combine system views with regular user data. This might come as a surprise, but behind the scenes the system data is not stored in your warehouse itself, but in a separate storage. For the moment, the query engine is not able to process queries that mix those two.
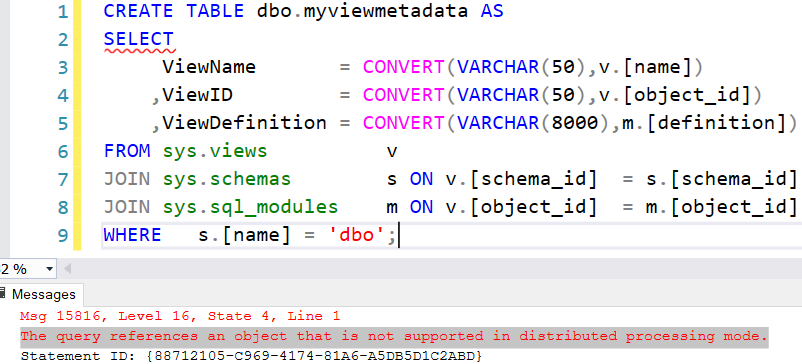
Alright, let’s try something else: dumping the metadata into my own table. Alas:
Whatever your insert type is of your SQL statement, it doesn’t work. Seems like we’re stuck when you want to use SQL only. My current work around is to use a pipeline with a Copy activity that reads the metadata as the source, and writes it to a table in the sink. Unfortunately, not the fastest option since a pipeline can’t write to a warehouse table directly; the data needs to be staged first.
Luckily, this is only a temporary work around as Microsoft is aware of the problem and is working on a solution. At the time of writing, the timeline is not yet know, but keep an eye on the Fabric roadmap.
I'm starting a webinar series about SQL Server indexing with the fine folks of MSSQLTips.com.…
A while ago I blogged about a use case where a pipeline fails during debugging…
Quite the title, so let me set the stage first. You have an Azure Data…
At Saturday the 21st of February I'm presenting an introduction to dimensional modelling at dataMinds…
I'm not trying to start up a debate whether you should use tabs or spaces…
The Power BI Enhanced Report Format (PBIR) will soon become the default, and that's a…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
View Comments
Thanks, this is good to know about, as I frequently rely on metadata-driven approaches.
One note, you may wish to revise the malformed sentence,
"Whatever your insert type is of your SQL statement it work."
Otherwise, it's a helpful article!
Hi Mike,
thanks for pointing out the typo. I've corrected it.
Koen,
Thank you for this thread.. I was racking my brain trying all variations of inserting sys output into a table. Nothing worked... Your thread helped to confirm my wasted efforts on trying to capture the results as a table. Fabric, after all, does not allow temp tables either. It's too bad we can't capture it as variables..................
But wait... we can. What if... JSON!!!
DECLARE @json NVARCHAR(MAX);
SELECT @json = output
FROM (
SELECT
CONVERT(VARCHAR(50), v.[name]) AS ViewName,
CONVERT(VARCHAR(50), v.[object_id]) AS ViewID,
CONVERT(VARCHAR(8000), m.[definition]) AS ViewDefinition
FROM sys.views v
JOIN sys.schemas s ON v.[schema_id] = s.[schema_id]
JOIN sys.sql_modules m ON v.[object_id] = m.[object_id]
WHERE s.[name] = 'dbo'
FOR JSON AUTO
) JSON (output)
SELECT *
FROM OPENJSON(@json) WITH (
ViewName VARCHAR(50) '$.ViewName',
ViewID VARCHAR(50) '$.ViewID',
ViewDefinition VARCHAR(8000) '$.ViewDefinition'
);
Hope this hack helps!!! In my case, the sheer number of tables I'm attempting to capture schema drift on makes the Queuing process in ADF an unacceptable solution.