In many ERP software you have the concept of “companies” or “divisions”, a way of logically dividing resources and assets. For example, if you have a company and a sister-company, you can create two divisions to keep everything separate. When you read data from an Exact Online API endpoint, you need to specify for which division you want the data. We are going to structure our pipelines so that we loop over the divisions, pulling all data from each division. To do this, we need a reference dataset of all available divisions. The pipeline takes the following format:
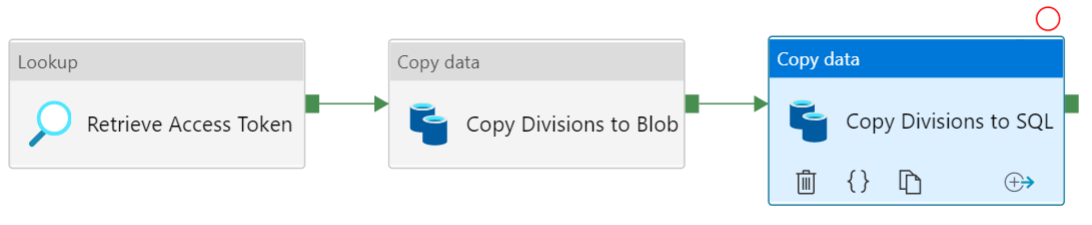
The first step is retrieving the current access token. Make sure you created and run the pipeline from the previous post so there’s a current access token in the database (remember it’s only valid for 10 minutes). Using a Lookup Activity, we can fetch the access token.
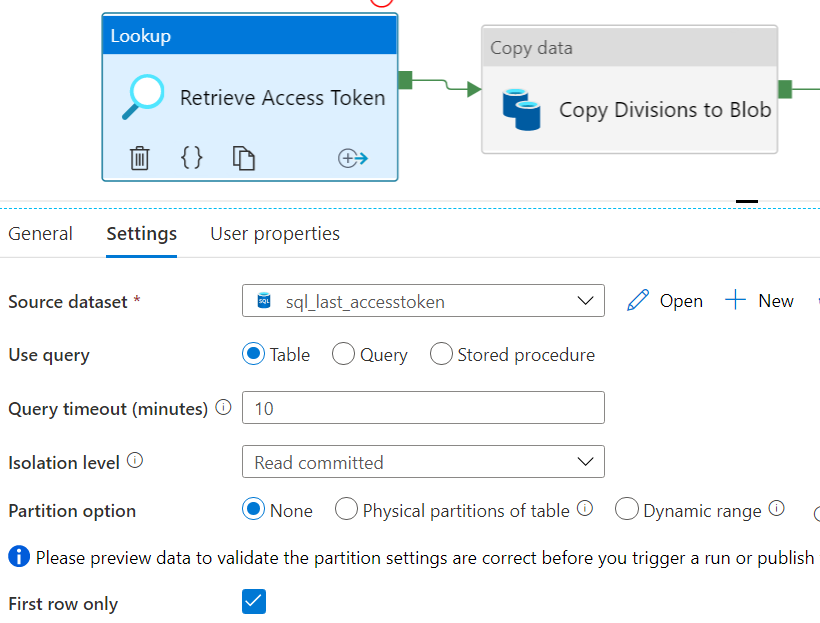
You can either create a new dataset for the access token table, or you can just reuse any dataset that points to the correct database and specify a query instead. You can for example reuse the dataset from the previous post. To fetch the divisions, we need either a REST dataset or an HTTP dataset (if we’re using the XML API). Using the REST API, you can use the endpoint /api/v1/{division}/system/Divisions to get the divisions accessible to the user that granted the app permission, or the endpoint /api/v1/{division}/system/AllDivisions to get the full list of divisions for the current license. Problem with both endpoints is that need to pass a division number into the URL. This might not be an obstacle if you already know such a division number, but in my case I didn’t know any of the internal division numbers and they’re not easy to find in the Exact Online software (you only see the division code there, which is not the same as the division number). So I opted to use the XML API, which gives you a full list of divisions.
We need an HTTP dataset, of the type XML:
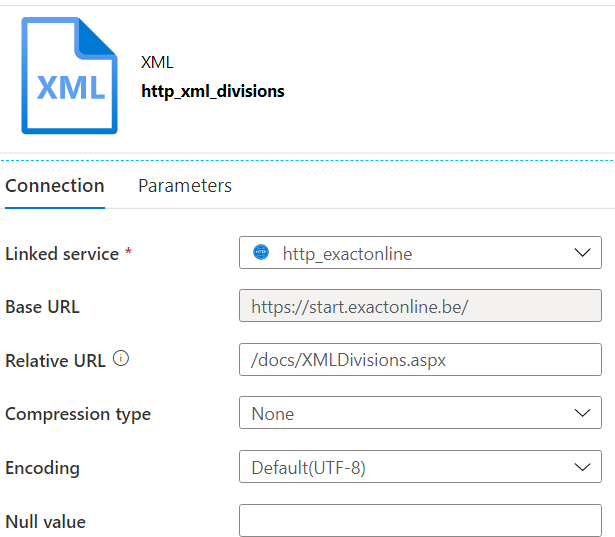
The relative URL is /docs/XMLDivisions.aspx. In a browser where you’re logged into Exact Online, you can go to this URL and you’ll retrieve an XML list of the divisions in the browser itself.
The next activity in the pipeline is a Copy Activity. As the source, you have the HTTP dataset.
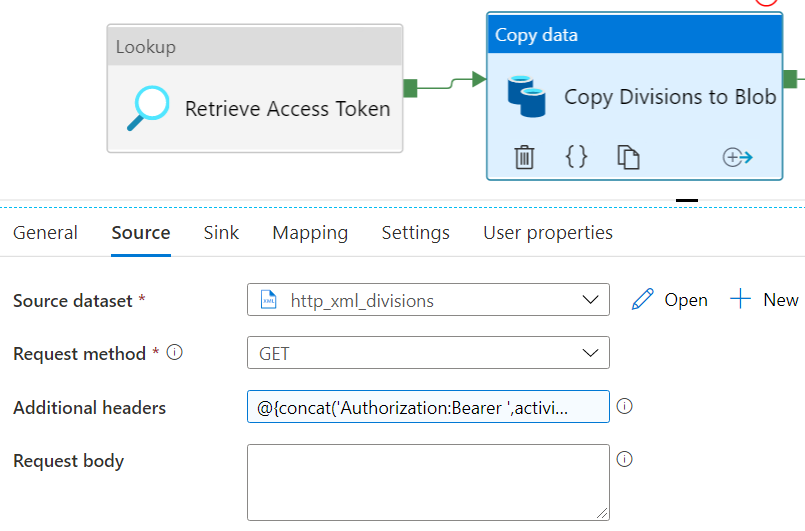
The request method is GET and the following expression is used for the additional headers property:
@{concat('Authorization:Bearer ',activity('Retrieve Access Token').output.FirstRow.AccessToken)}
This header sets the Authorization header to the following value: Authorization:Bearer xxxxx. Where xxxxx is the value of the access token. As a sink, I used Azure Blob Storage. I might’ve directly written to the database instead, but other people needed the list of divisions as well, so I’m dropping all data into a central data lake first. So we need an Azure Blob Storage Linked Service:
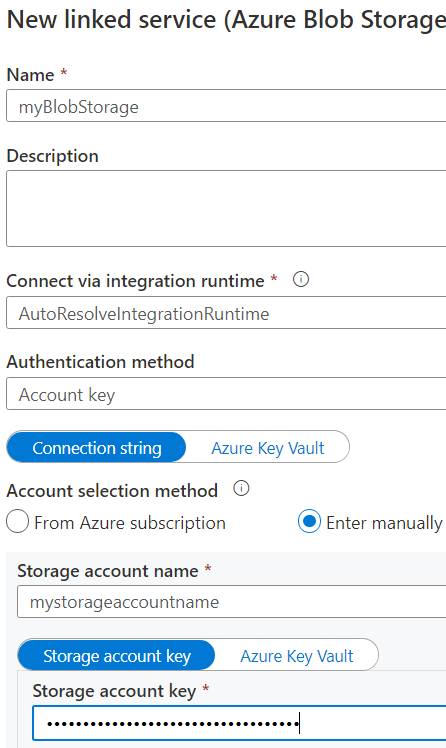
Next, we create a CSV dataset on top of this Blob Storage:
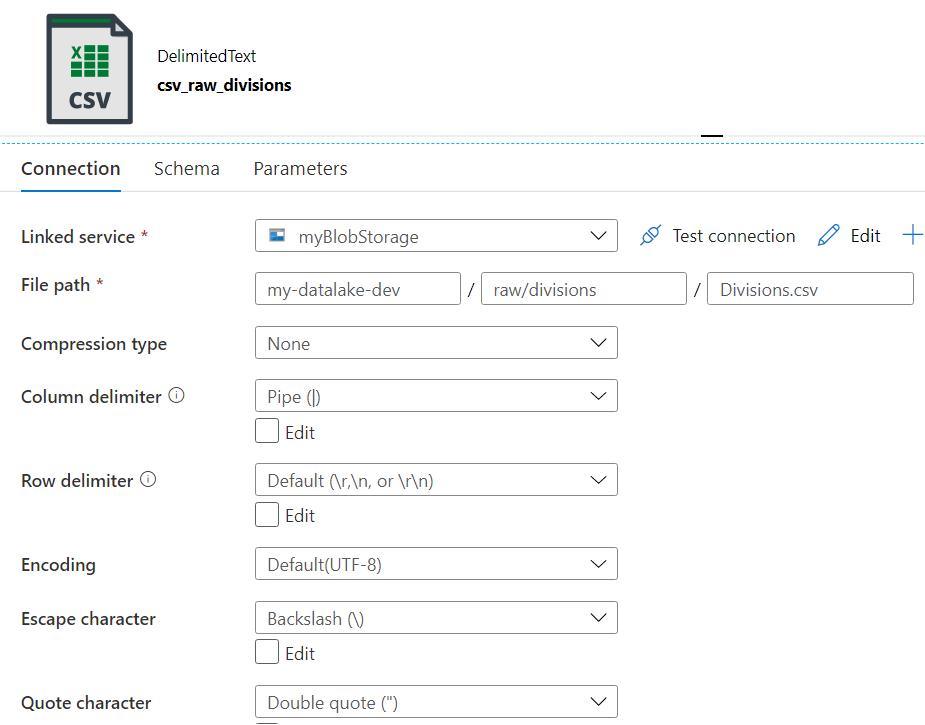
The divisions will be written to a file called Divisions.csv, which is located in a folder Divisions. This folder is located in a parent folder “raw”, which is used for the raw layer of the data lake, meaning all data ingested as-is. The reason why we’re not keeping the data in the XML format is that at the time of writing, XML in Blob Storage is not a supported file format as a sink. Since the Copy Activity can flatten the XML into a CSV file, that’s my preferred option. You don’t need to define or import the schema of the CSV file.
Now we can configure the sink of the Copy Acticity.
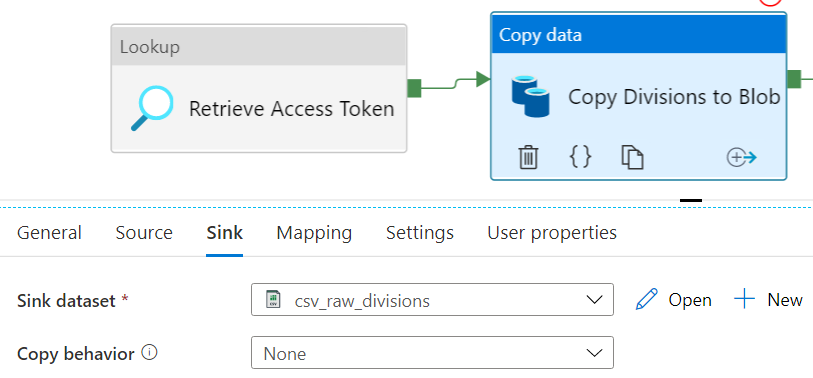
In the Mapping pane, click on Import Schemas. You’ll be asked to provide a value for the access token.
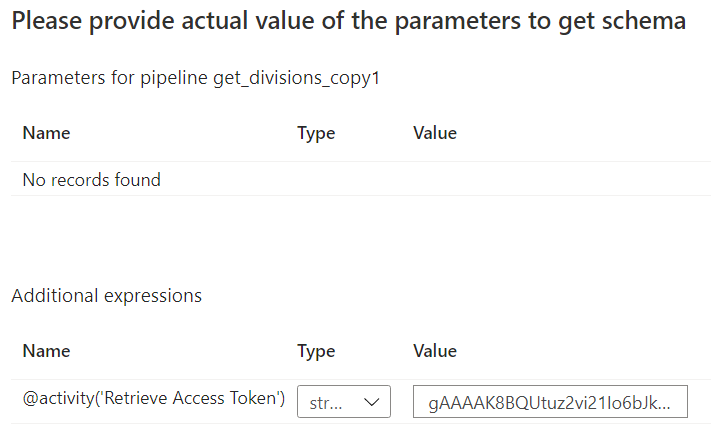
ADF will fetch the metadata from the XML API. Make sure the collection reference is set to $[‘Administrations’][‘Administration’] (administration is a synonym for divisions here).
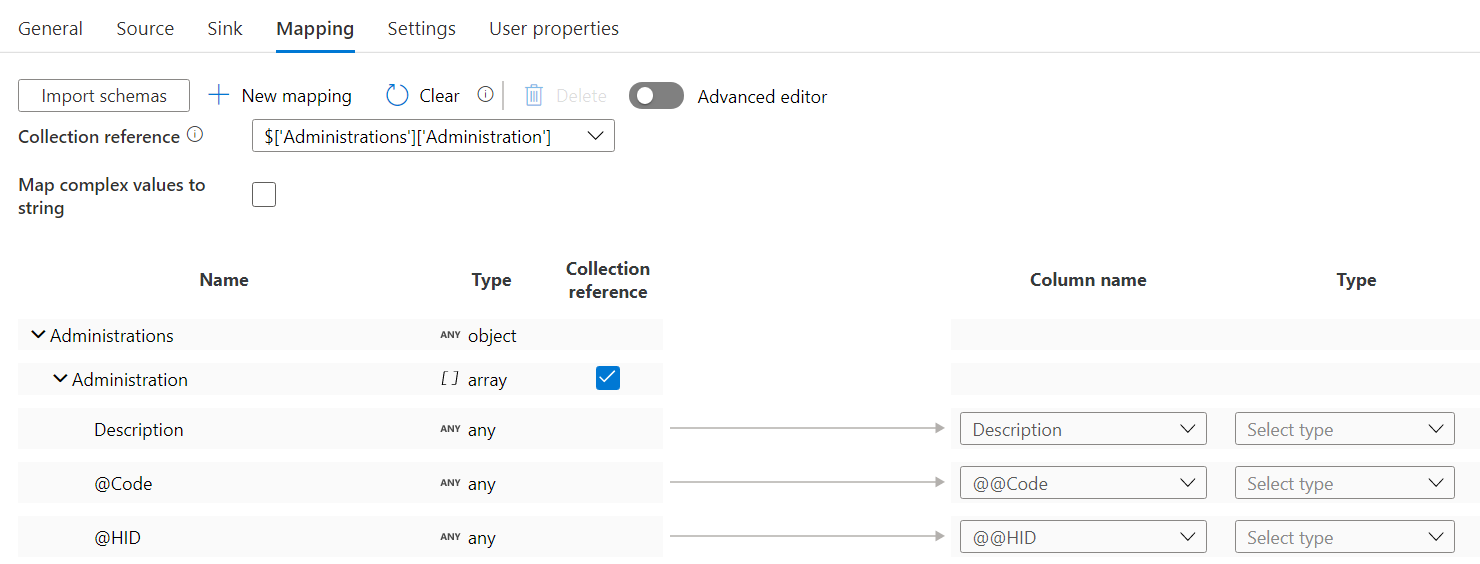
In the far right column, choose data types for the three fields. Since the sink is a CSV file, I choose string for all fields. Finally I added one more Copy Activity, to copy the Divisions into a table in the Azure SQL DB. Again, dumping the data into Blob Storage is optional, and you might want to copy the data directly from the XML API to the database. For the source, I used the same CSV dataset as the one we used in the sink of the previous Copy Activity.
For the sink, I created an Azure SQL DB dataset:
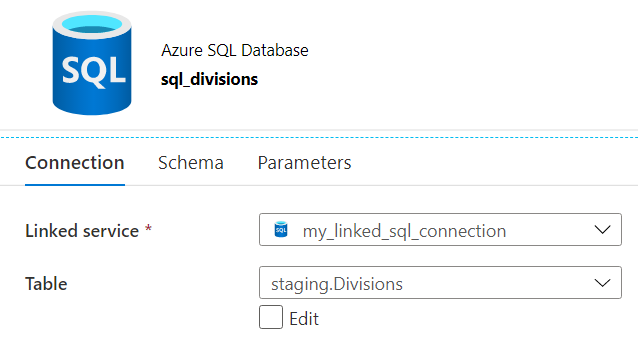
This table has three columns:
The configuration of the sink now looks like this:
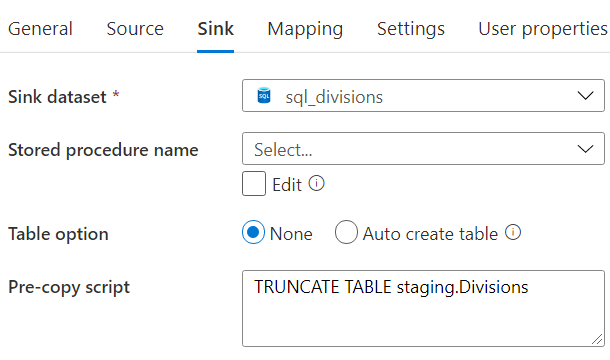
And the mapping pane:
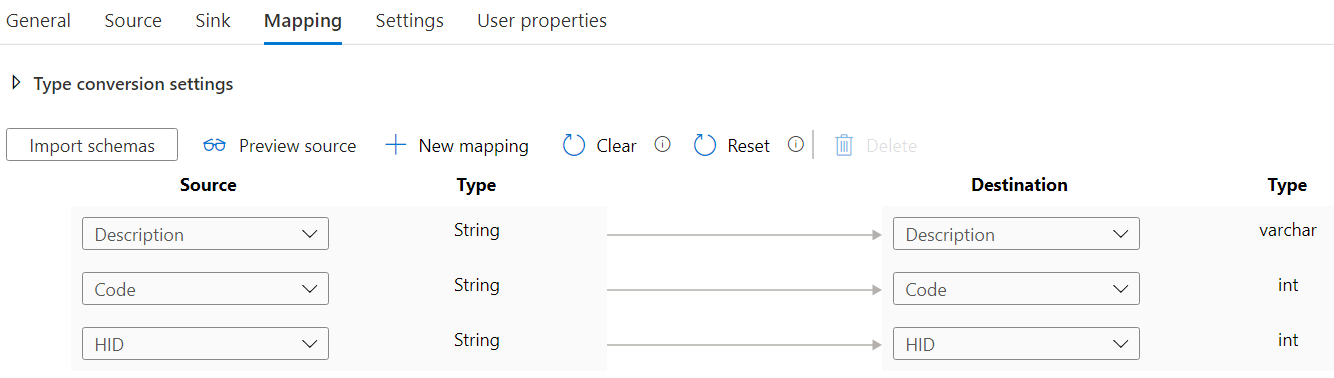
The pipeline is now finished. When we run it, the Divisions are fetched from the XML API, written to Blob Storage and then written to a table in an Azure SQL DB. The data in the CSV file should look like this:
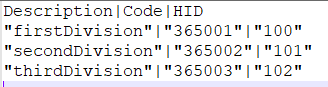
Getting this pipeline right as crucial, as all other pipelines fetching data from the REST API need the division codes.
Related Posts
------------------------------------------------
Do you like this blog post? You can thank me by buying me a beer 🙂
You can find the current division number by using this api call:
https://start.exactonline.be/api/v1/current/Me
Hi Wouter,
thanks for your comment. I’m still happy with my XML endpoint because this allows me to retrieve all divisions in one step 🙂
Koen