Originally this blog post would be titled “Disabling aggregations over a parent-child hierarchy”, but I thought it could create confusion with the Aggregation Design concept in Analysis Services (SSAS), which is something completely different.
What I want to describe in this blog post is a method forcing a parent-child hierarchy in SSAS to show the parent’s own data value, instead of the sum of the aggregated values of its children. Why would I want to do such a thing? A client of mine once asked me to create a cube on some financial data. However, the data was delivered by a 3rd party and could not be changed. This means that a parent-child hierarchy – for example the chart of accounts on a Profit&Loss report – should display the values from the database, not values calculated or aggregated by SSAS. In most cases the values would have been the same, but sometimes they wouldn’t, hence the need to create an alternative solution.
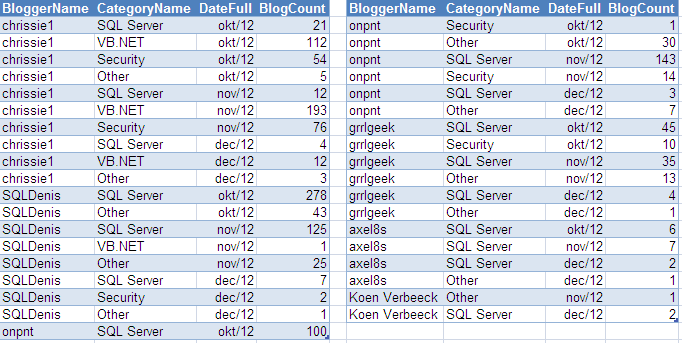
Basically I want to create some sort of semi-additive measure, which aggregates values for all dimensions, except the parent-child hierarchy. In this blog post I use sample data regarding some of the bloggers on the LessthanDot site:
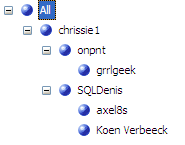
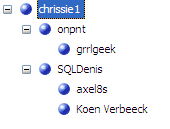
The bloggers themselves have the following parent-child hierarchy. (Disclaimer: this is just a fabricated sample. It doesn’t represent any actual hierarchy :))
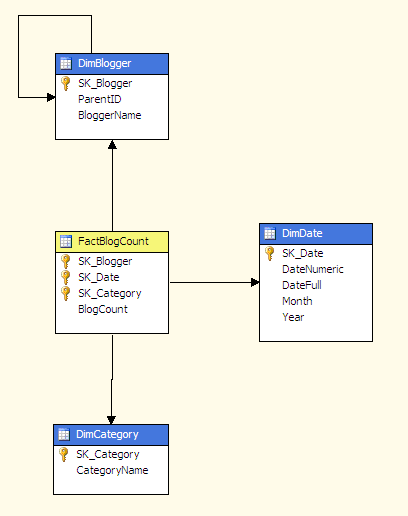
The following star schema is used to build the cube:
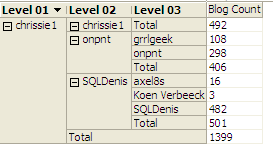
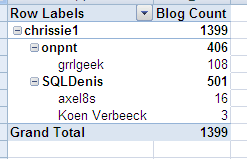
With the default values configured in the SSAS cube, we get this pivot table:
We can see SSAS has aggregated the values of the children to the parents, which is incorrect in our case. For example, at the time of writing SQLDenis had written 482 blog posts, not 501. Every parent is also repeated: once with the calculated aggregated value and once with its actual value. This tends to be very confusing for end users, so we want to avoid this.
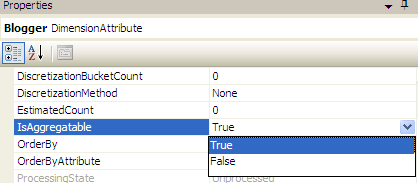
IsAggregatable
This is a dimension attribute property with a very promising name. However, the only visible effect it has is supplying an(All) level on the attribute hierarchy if this property is set to True.
If we set this property to False, we get the following hierarchy:
The All member is gone, Chrissie is at the top, but the results are still the same when we browse the cube:
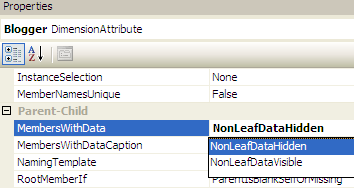
MembersWithData
This parent-child hierarchy property specifies how members with data are treated. We have two options:NonLeafDataVisible (the default) and NonLeafDataHidden.
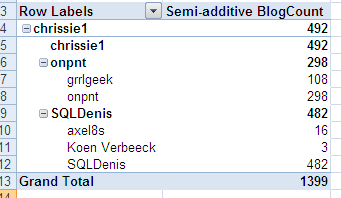
The default specifies if a parent has data, the parent is repeated as a child of its own. The child value will have the actual data, while the parent value will show the aggregated value of all its children. The NonLeafDataHidden setting will cause the parent-child hierarchy to show only the actual children of a parent and the parent itself with the aggregated value. This gives the following result in our sample:
This is even worse, as it’s not clear how a parent gets its value. For example, blogger onpnt has a value of 406, but grrlgeek has the value 108. The pivot table does not show how the value 406 is calculated, again leading to much confusion.
Defining our semi-additive measure
SSAS has the possibility to define semi-additive measures – at least in the Enterprise edition for SQL Server 2008 R2 – but unfortunately this doesn’t work for our case: only the time dimension can be taken into account for semi-additive behavior.
So we need create our own calculated semi-additive measure. The following MDX does the trick:
([Blogger].[Blogger].CURRENTMEMBER.DATAMEMBER,[Measures].[Blog Count])
This calculated measure is the tuple of the normal additive measure Blog Count with the current data member of the parent-child hierarchy Blogger. This forces the cube to take the actual value of a member in the hierarchy instead of calculating an aggregate. We now get the following results:
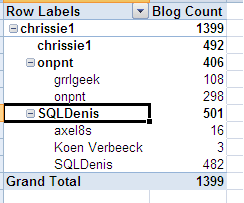
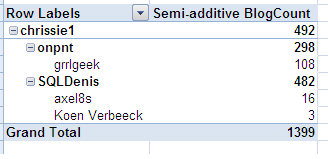
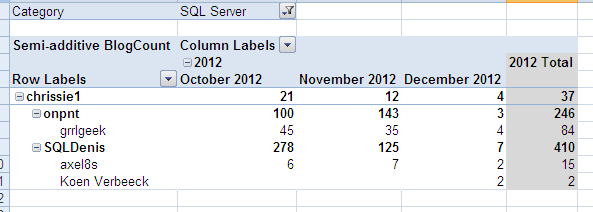
We are on the right track: each parent displays its own actual value. However, the parents are duplicated. Remember the NonLeafDataHidden property? Let’s use this to get rid of those extra child members:
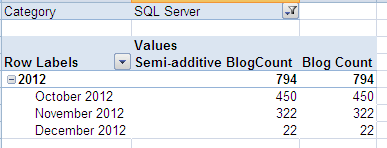
Now every member of the parent-child hierarchy displays its own data. The semi-additive behavior of this solution is confirmed when browsing other dimensions:
There’s no difference between our calculated measure and the normal measure defined in the measure group. We can mix all the dimensions together and the values are still displayed correctly:
Conclusion
We can define semi-additive behavior on a parent-child hierarchy with a fairly easy calculated measure. The downside is that you end up with two measures in your cube: a correct one and a not entirely correct one from an end user point of view. This can be solved by using perspectives, if applicable.
Note: the sample project can be downloaded here.
I'm starting a webinar series about SQL Server indexing with the fine folks of MSSQLTips.com.…
A while ago I blogged about a use case where a pipeline fails during debugging…
Quite the title, so let me set the stage first. You have an Azure Data…
At Saturday the 21st of February I'm presenting an introduction to dimensional modelling at dataMinds…
I'm not trying to start up a debate whether you should use tabs or spaces…
The Power BI Enhanced Report Format (PBIR) will soon become the default, and that's a…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}