With “dynamic datasets” I mean the following: a dataset that doesn’t have any schema or properties defined, but rather only parameters. Why would you do this? With a dynamic – or generic – dataset, you can use it inside a ForEach loop and then loop over metadata which will populate the values of the parameter. An example: you have 10 different files in Azure Blob Storage you want to copy to 10 respective tables in Azure SQL DB. Instead of creating 20 datasets (10 for Blob and 10 for SQL DB), you create 2: one dataset for Blob with parameters on the file path and file name, and 1 for the SQL table with parameters on the table name and the schema name. You store the metadata (file name, file path, schema name, table name etc) in a table. You read the metadata, loop over it and inside the loop you have a Copy Activity copying data from Blob to SQL. Two datasets, one pipeline. Boom, you’re done.
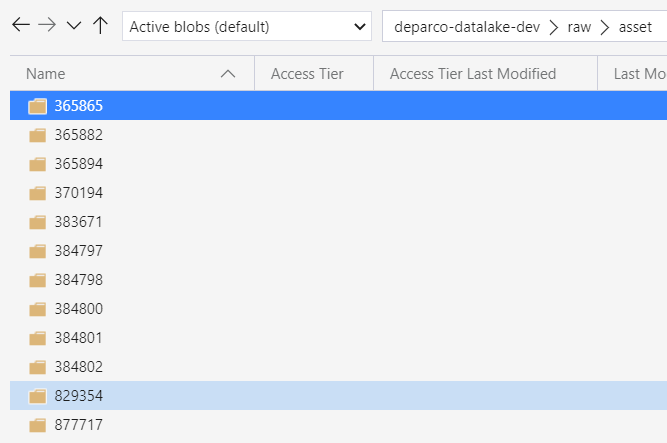
Let’s walk through the process to get this done. As an example, I’m taking the output of the Exact Online REST API (see the blog post series). When you read an API endpoint, it stores a file inside a folder with the name of the division. If you have 10 divisions, you get 10 folders with a file inside each of them.
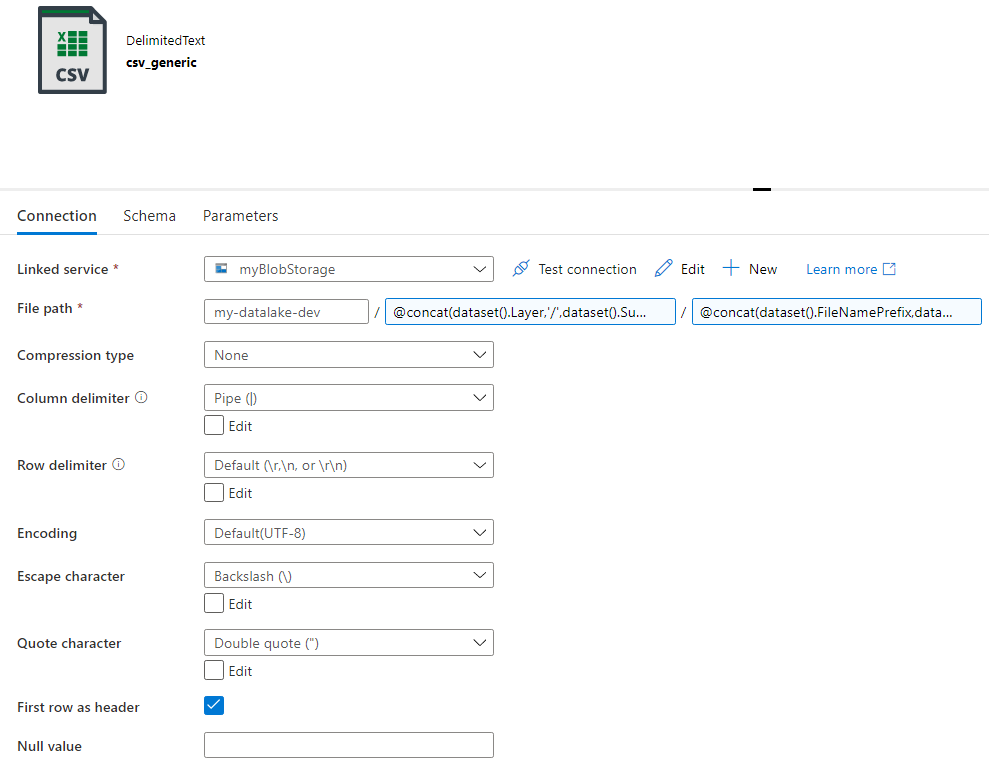
To make life of our users who are querying the data lake a bit easier, we want to consolidate all those files into one single file. We are going to put these files into the “clean” layer of our data lake. Both source and sink files are CSV files. This means we only need one single dataset:
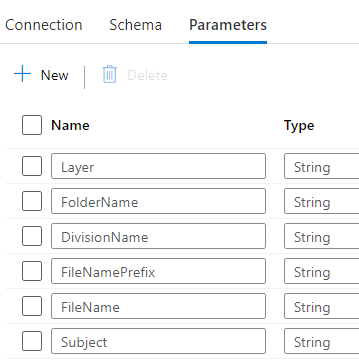
These are the parameters:
The expression for the file path:
@concat(dataset().Layer,'/',dataset().Subject,dataset().DivisionName,dataset().FolderName)
This expression will allow for a file path like this one: mycontainer/raw/assets/xxxxxx/2021/05/27. Foldername can be anything, but you can create an expression to create a yyyy/mm/dd folder structure:
@concat('/',formatDateTime(utcnow(),'yyyy/MM/dd'))
The expression for the file name:
@concat(dataset().FileNamePrefix,dataset().FileName)
Again, with the FileNamePrefix you can create a timestamp prefix in the format of the “hhmmss_” format:
@concat('/',formatDateTime(utcnow(),'hhmmss'),'_')
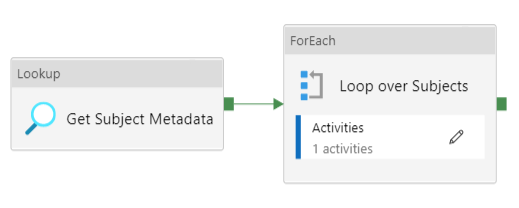
The main pipeline has the following layout:
In the Lookup, we retrieve a list of the subjects (the name of the REST API endpoints):
In the ForEach Loop, we use the following expression to get the values to loop over:
@activity('Get Subject Metadata').output.value
Inside the ForEach Loop, we have a Copy Activity.
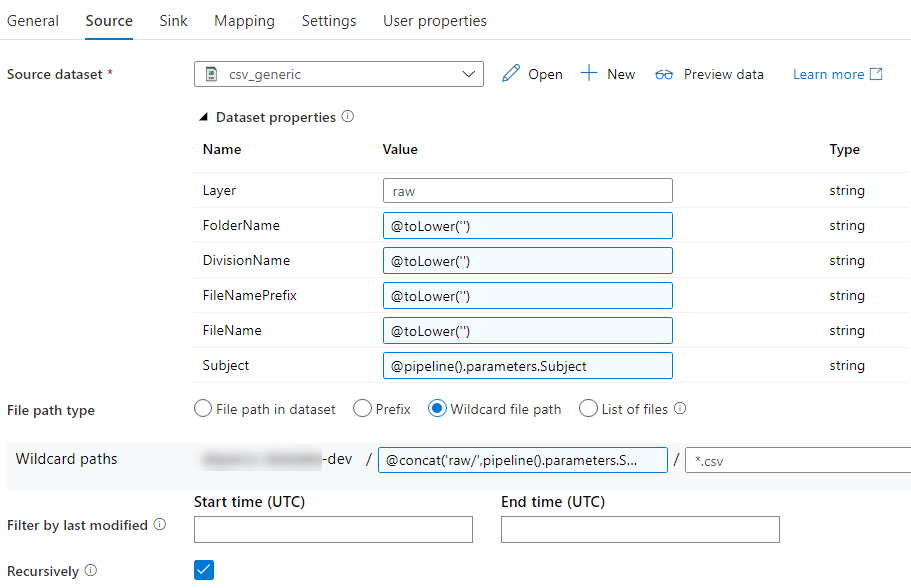
In the Source pane, we enter the following configuration:
Most parameters are optional, but since ADF doesn’t understand the concept of an optional parameter and doesn’t allow to directly enter an empty string, we need to use a little work around by using an expression: @toLower(”). Only the subject and the layer are passed, which means the file path in the generic dataset looks like this: mycontainer/raw/subjectname/.
However, we need to read files from different locations, so we’re going to use the wildcard path option. The file path field has the following expression:
@concat('raw/',pipeline().parameters.Subject,'/*')
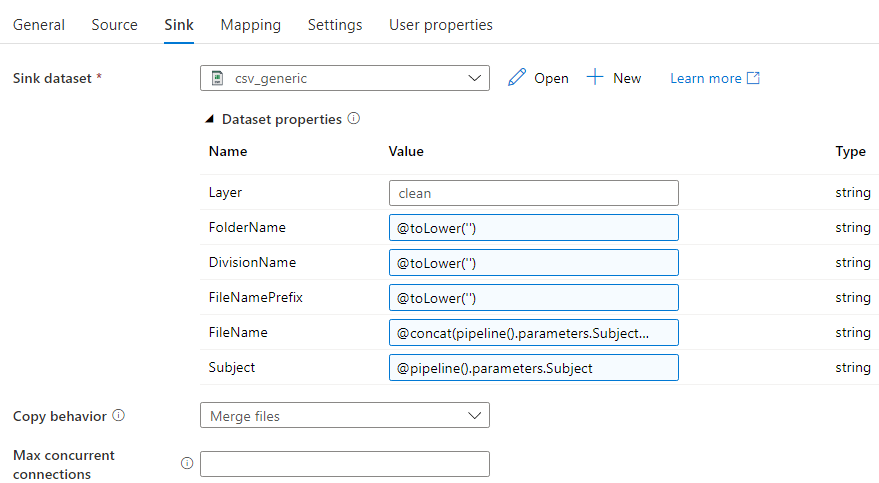
The full file path now becomes: mycontainer/raw/currentsubjectname/*/*.csv. Since the recursively option is enabled, ADF will traverse the different folders of all divisions and their subfolders, picking up each CSV file it finds. For the sink, we have the following configuration:
The layer, file name and subject parameters are passed, which results in a full file path of the following format: mycontainer/clean/subjectname/subject.csv. The Copy behaviour is set to Merge files, because the source may pick up multiple files, but the sink will only be one single file. Since we’re dealing with a Copy Activity where the metadata changes for each run, the mapping is not defined. ADF will do this on-the-fly.
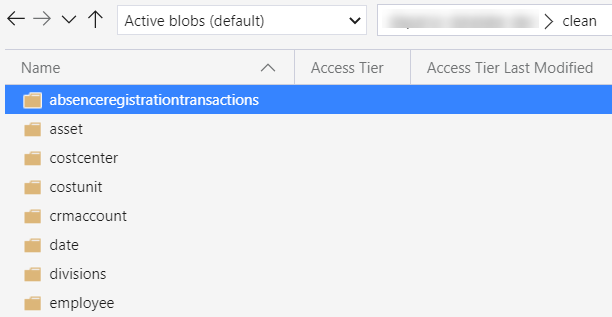
When we run the pipeline, we get the following output in the clean layer:
Each folder will contain exactly one CSV file:
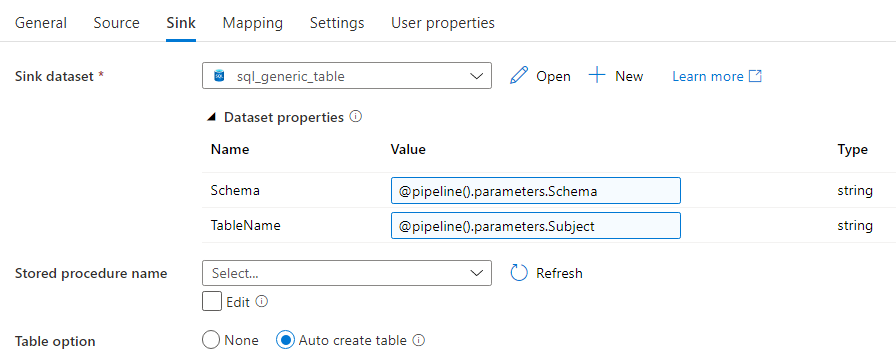
You can implement a similar pattern to copy all clean files into their respective staging tables in an Azure SQL DB. The same pipelines structure is used, but the Copy Activity will now have a different source and sink. The source (the CSV file in the clean layer) has the exact same configuration as the sink in the previous set-up. The sink looks like this:
The dataset of the generic table has the following configuration:
With the following two parameters:
For the initial load, you can use the “Auto create table” option. ADF will create the tables for you in the Azure SQL DB. Since the source is a CSV file, you will however end up with gems like this:
You can change the data types afterwards (make sure string columns are wide enough), or you can create your tables manually upfront. Or don’t care about performance. Once the tables are created, you can change to a TRUNCATE TABLE statement for the next pipeline runs:
@concat('TRUNCATE TABLE ',pipeline().parameters.Subject, '.', pipeline().parameters.Subject)
Again, no mapping is defined. And that’s it! Run the pipeline and your tables will be loaded in parallel.
I'm starting a webinar series about SQL Server indexing with the fine folks of MSSQLTips.com.…
A while ago I blogged about a use case where a pipeline fails during debugging…
Quite the title, so let me set the stage first. You have an Azure Data…
At Saturday the 21st of February I'm presenting an introduction to dimensional modelling at dataMinds…
I'm not trying to start up a debate whether you should use tabs or spaces…
The Power BI Enhanced Report Format (PBIR) will soon become the default, and that's a…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
View Comments
Hi,
thanks for these articles.
I'm actually trying to do a very simple thing: copy a json from a blob to SQL.
The json is an array of objects, but each object has a few properties that are arrays themselves.
I want to copy the '1st level' json to SQL, after which I will do further processing on the sql side if needed.
It seems I cannot copy the array-property to nvarchar(MAX)
Any ideas? Thanks
Hi Wouter,
is it possible to give a (fake) example of your JSON structure?
Koen
Thanks for your post Koen,
Did I understand correctly that Copy Activity would not work for unstructured data like JSON files ? (being the objective to transform a JSON file with unstructured data into a SQL table for reporting purposes.
Thank you in advance!
You can make it work, but you have to specify the mapping dynamically as well. You can read more about this in the following blog post: https://sqlkover.com/dynamically-map-json-to-sql-in-azure-data-factory/