This is the final blog post of this series on how to extract data from the Exact Online REST API with Azure Data Factory. I’ve you followed along with the previous posts, you’ve seen how you can request new refresh/access tokens from the API, how you can extract data from an endpoint for multiple divisions at the same time and how you can set up pagination.
There’s one pesky limit of the API which we haven’t dealt with: the access token is only valid for 10 minutes. If you’re setting up a data pipeline that will extract data from multiple endpoints, 10 minutes is rather short. In one project, there wasn’t much data so the pipeline finished in about 5-6 minutes. Great, I didn’t have to spend time on that access token limit. Until one weekend where for some reason the API was slower and the total pipeline duration went over 10 minutes (and of course this happens in the weekend and not in the work week). If this happens, the API requests will fail with a 401 HTTP error.
There are probably multiple solutions to this problem. This is the one I’ve come up with:
This is the main pipeline:
You get the access token first, then the divisions and then you can start each pipeline sequentially. I wanted to use a ForEach loop to loop over the different endpoints and call the relevant pipeline, but apparently it’s currently not possible to use an expression on a Execute Pipeline activity. Boo. You can vote for this feature here.
Such a pipeline for retrieving data from the API looks like this:
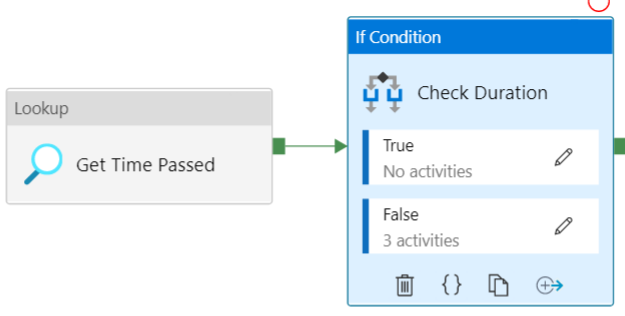
The first three steps are explained in this blog post. A final activity has been added: a pipeline that checks the duration. This one has the following format:
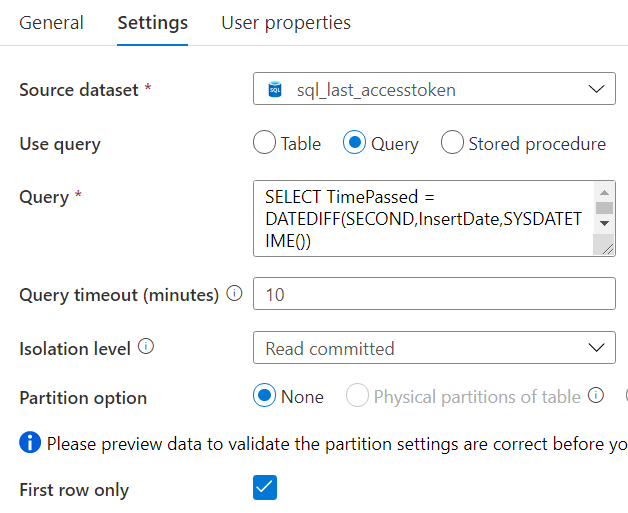
First we retrieve the time that has passed since the access token has been inserted into the database. This is not 100% the time since the access token was generated, which is why we stop when we have less than 2 minutes available.
The following query is used:
SELECT TimePassed = DATEDIFF(SECOND,InsertDate,SYSDATETIME()) FROM etl.[AccessToken];
This returns the number of seconds since the access token was inserted into the database. The InsertDate column has a default constraint of SYSDATETIME(). In the “If Condition” activity, we check if the number we retrieved from the previous step is smaller than 480 (8 * 60), with the following expression:
@lessOrEquals(activity('Get Time Passed').output.FirstRow.TimePassed,480)
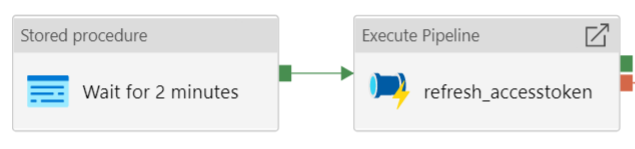
If the result is True, it means we have at least 2 minutes left to run another pipeline. If the result is False, we have less than 2 minutes and this is probably too short for another pipeline. In this case, the following “subpipeline” is run:
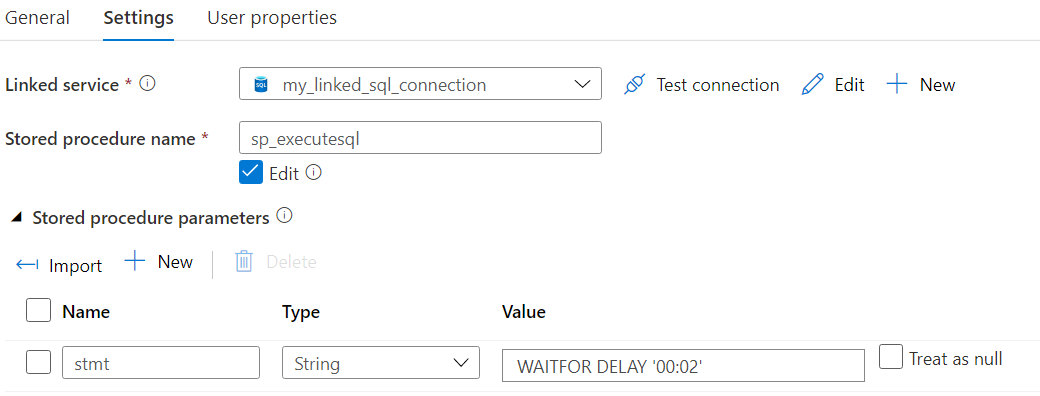
We wait for 2 minutes, just to make sure we’re over the 10 minute limit. Then a new token pair is requested. We can wait using the T-SQL WAITFOR DELAY statement:
With this addition to the pipelines, you should be able to run a main pipeline that goes over 10 minutes without any problems.
Related Posts
I'm starting a webinar series about SQL Server indexing with the fine folks of MSSQLTips.com.…
A while ago I blogged about a use case where a pipeline fails during debugging…
Quite the title, so let me set the stage first. You have an Azure Data…
At Saturday the 21st of February I'm presenting an introduction to dimensional modelling at dataMinds…
I'm not trying to start up a debate whether you should use tabs or spaces…
The Power BI Enhanced Report Format (PBIR) will soon become the default, and that's a…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
View Comments
Hi Koen,
thanks for your extensive blog on this topic. I myself am running into a problem with a very large table that takes more than 10 minutes to load. So the access token expires during the load. I do refresh the accestoken after 9,5 minutes but it seems that the authorization header is not updated during pagination? Or am I missing something?
Hi Wilfred,
I haven't run into the problem myself (yet), but I don't think the authorization header is updated while the activity is already running.
One option might be to load the table incrementally if that's an option. I had to switch one API endpoint to incremental loading because I was going over the API limit of x number of requests per minute due to all the paging.
Basically you can filter on a date (most likely the modified date) to get only a range of data from the endpoint.
Regards,
Koen
Hi Koen,
that is indeed a possibility, for example load with a filter on FinancialYear. In case of 'keeping a database in sync with Exact Online' Exact recommends the use of Sync API's. With those API's you only retrieve the new and updates rows. But of course you need a initial/first load and those Sync api's don't accept any filters but the TimeStamp. Then I thought, maybe then the initial load via the bulk api incrementally on FinancialYear, but unfortunately the bulk APIs don't have the TimeStamp which is necessary for the Sync API's. So for the moment i am stuck and will try to contact Exact Support.
Well, good luck with that :)
Hi Wilfred, you can just start with Timestamp = 1 and do a full load from the Sync API. If you somehow pass the 10 minutes you can query a Max(Timestamp) from your table and execute the Sync API again with this new Timestamp value.
Hi Johan,
yeah, i tried that. Had to start the proces 5 times to get > 1M rows. But ended up with a few 100 double Unique ID's, so i got a little uncomfortable ;-). Now that I think about it, maybe you may need to do this if no transactions are taking place within the table. Which is a bit tricky with a 24/7 webshop. I will try this again after consultation with the customer...
Hello Wilfres,
Have you found the solution to your problem?